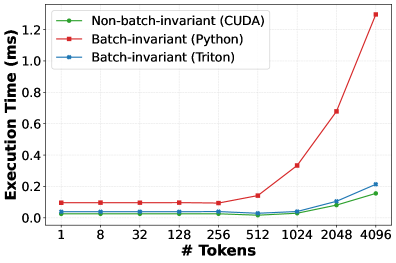
## Line Chart: Execution Time vs. Number of Tokens
### Overview
The image is a line chart comparing the execution time (in milliseconds) of three different implementations (CUDA, Python, and Triton) as the number of tokens increases. The chart shows how the execution time scales with the number of tokens for each implementation.
### Components/Axes
* **X-axis:** "# Tokens" with values 1, 8, 32, 128, 256, 512, 1024, 2048, 4096.
* **Y-axis:** "Execution Time (ms)" with values ranging from 0.0 to 1.2 in increments of 0.2.
* **Legend (Top-Left):**
* Green: Non-batch-invariant (CUDA)
* Red: Batch-invariant (Python)
* Blue: Batch-invariant (Triton)
### Detailed Analysis
* **Non-batch-invariant (CUDA) - Green Line:**
* Trend: Relatively flat initially, then increases slightly.
* Data Points:
* 1 Token: ~0.03 ms
* 8 Tokens: ~0.03 ms
* 32 Tokens: ~0.03 ms
* 128 Tokens: ~0.03 ms
* 256 Tokens: ~0.03 ms
* 512 Tokens: ~0.02 ms
* 1024 Tokens: ~0.03 ms
* 2048 Tokens: ~0.09 ms
* 4096 Tokens: ~0.15 ms
* **Batch-invariant (Python) - Red Line:**
* Trend: Relatively flat initially, then increases sharply.
* Data Points:
* 1 Token: ~0.10 ms
* 8 Tokens: ~0.10 ms
* 32 Tokens: ~0.10 ms
* 128 Tokens: ~0.10 ms
* 256 Tokens: ~0.10 ms
* 512 Tokens: ~0.13 ms
* 1024 Tokens: ~0.33 ms
* 2048 Tokens: ~0.68 ms
* 4096 Tokens: ~1.25 ms
* **Batch-invariant (Triton) - Blue Line:**
* Trend: Relatively flat initially, then increases.
* Data Points:
* 1 Token: ~0.09 ms
* 8 Tokens: ~0.09 ms
* 32 Tokens: ~0.09 ms
* 128 Tokens: ~0.09 ms
* 256 Tokens: ~0.09 ms
* 512 Tokens: ~0.02 ms
* 1024 Tokens: ~0.03 ms
* 2048 Tokens: ~0.08 ms
* 4096 Tokens: ~0.21 ms
### Key Observations
* For a small number of tokens (1-512), all three implementations have relatively low and similar execution times.
* The Batch-invariant (Python) implementation shows a significant increase in execution time as the number of tokens increases beyond 512.
* The Non-batch-invariant (CUDA) and Batch-invariant (Triton) implementations scale much better than the Python implementation, with the CUDA implementation showing the lowest execution time for a large number of tokens.
### Interpretation
The chart demonstrates the performance differences between CUDA, Python, and Triton implementations when processing varying numbers of tokens. The Python implementation's poor scaling suggests it is not suitable for processing large sequences of tokens. CUDA and Triton offer better performance, with CUDA being the most efficient for large token counts in this specific scenario. The "batch-invariant" and "non-batch-invariant" labels likely refer to how the implementations handle batch processing, with the non-batch-invariant CUDA implementation being optimized for single-sequence processing.