\n
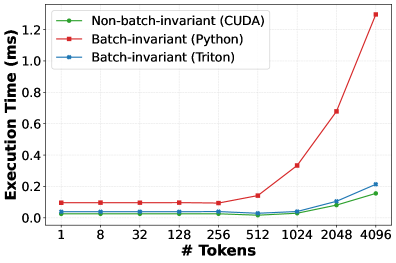
## Line Chart: Execution Time vs. Number of Tokens
### Overview
This line chart compares the execution time (in milliseconds) of three different implementations – Non-batch-invariant (CUDA), Batch-invariant (Python), and Batch-invariant (Triton) – as a function of the number of tokens processed. The chart visually demonstrates how execution time scales with increasing token count for each implementation.
### Components/Axes
* **X-axis:** "# Tokens" - Represents the number of tokens, with markers at 1, 8, 32, 128, 256, 512, 1024, 2048, and 4096.
* **Y-axis:** "Execution Time (ms)" - Represents the execution time in milliseconds, ranging from 0 to 1.2 ms.
* **Legend:** Located in the top-left corner, identifies the three data series:
* Non-batch-invariant (CUDA) - Represented by a green line with circle markers.
* Batch-invariant (Python) - Represented by a red line with circle markers.
* Batch-invariant (Triton) - Represented by a blue line with circle markers.
* **Gridlines:** A light gray grid is present to aid in reading values.
### Detailed Analysis
* **Non-batch-invariant (CUDA) - Green Line:** The line starts at approximately 0.03 ms at 1 token and increases relatively linearly to approximately 0.23 ms at 4096 tokens.
* 1 Token: ~0.03 ms
* 8 Tokens: ~0.02 ms
* 32 Tokens: ~0.01 ms
* 128 Tokens: ~0.04 ms
* 256 Tokens: ~0.06 ms
* 512 Tokens: ~0.09 ms
* 1024 Tokens: ~0.14 ms
* 2048 Tokens: ~0.19 ms
* 4096 Tokens: ~0.23 ms
* **Batch-invariant (Python) - Red Line:** This line remains relatively flat from 1 to 512 tokens, around 0.08 ms. It then exhibits a steep increase, reaching approximately 1.25 ms at 4096 tokens.
* 1 Token: ~0.08 ms
* 8 Tokens: ~0.08 ms
* 32 Tokens: ~0.08 ms
* 128 Tokens: ~0.09 ms
* 256 Tokens: ~0.09 ms
* 512 Tokens: ~0.10 ms
* 1024 Tokens: ~0.22 ms
* 2048 Tokens: ~0.68 ms
* 4096 Tokens: ~1.25 ms
* **Batch-invariant (Triton) - Blue Line:** This line shows a gradual increase from approximately 0.04 ms at 1 token to approximately 0.21 ms at 4096 tokens.
* 1 Token: ~0.04 ms
* 8 Tokens: ~0.04 ms
* 32 Tokens: ~0.04 ms
* 128 Tokens: ~0.05 ms
* 256 Tokens: ~0.07 ms
* 512 Tokens: ~0.10 ms
* 1024 Tokens: ~0.13 ms
* 2048 Tokens: ~0.17 ms
* 4096 Tokens: ~0.21 ms
### Key Observations
* The Batch-invariant (Python) implementation exhibits the lowest execution time for small token counts (up to 512 tokens) but scales poorly with increasing token counts, becoming significantly slower than the other two implementations.
* The Non-batch-invariant (CUDA) implementation shows a consistent, linear increase in execution time with increasing token counts.
* The Batch-invariant (Triton) implementation demonstrates the most stable and efficient scaling, with a moderate increase in execution time as the number of tokens grows.
* The difference in execution time between the implementations becomes substantial at higher token counts (above 1024).
### Interpretation
The data suggests that for small workloads (few tokens), the Batch-invariant (Python) implementation is the fastest. However, as the workload increases, its performance degrades rapidly, likely due to the overhead associated with Python's interpreted nature and lack of inherent parallelism. The CUDA implementation provides a steady performance increase, indicating a more predictable scaling behavior. The Triton implementation appears to be the most scalable and efficient, maintaining relatively low execution times even with a large number of tokens. This suggests that Triton is well-suited for handling large-scale token processing tasks. The steep increase in Python's execution time at higher token counts highlights the benefits of using optimized, compiled implementations like CUDA and Triton for performance-critical applications. The choice of implementation depends on the expected workload size and the priority given to performance and scalability.