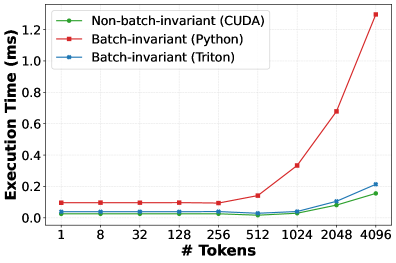
## Line Chart: Execution Time vs. Number of Tokens for Different Implementations
### Overview
The image is a line chart comparing the execution time (in milliseconds) of three different computational implementations as a function of the number of input tokens. The chart demonstrates how performance scales with increasing workload size.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:**
* **Label:** "# Tokens"
* **Scale:** Logarithmic (base 2), with major tick marks at 1, 8, 32, 128, 256, 512, 1024, 2048, and 4096.
* **Y-Axis:**
* **Label:** "Execution Time (ms)"
* **Scale:** Linear, ranging from 0.0 to 1.2 ms, with major tick marks every 0.2 ms.
* **Legend:** Positioned in the top-left corner of the plot area. It contains three entries:
1. **Non-batch-invariant (CUDA):** Green line with circular markers.
2. **Batch-invariant (Python):** Red line with square markers.
3. **Batch-invariant (Triton):** Blue line with diamond markers.
### Detailed Analysis
The chart plots three data series. Below is an analysis of each, including approximate data points extracted from the visual markers.
**1. Batch-invariant (Python) - Red Line with Squares:**
* **Trend:** The line is nearly flat for small token counts, then exhibits a sharp, accelerating upward curve starting around 256-512 tokens.
* **Data Points (Approximate):**
* 1 token: ~0.10 ms
* 8 tokens: ~0.10 ms
* 32 tokens: ~0.10 ms
* 128 tokens: ~0.10 ms
* 256 tokens: ~0.10 ms
* 512 tokens: ~0.15 ms
* 1024 tokens: ~0.35 ms
* 2048 tokens: ~0.70 ms
* 4096 tokens: ~1.30 ms (Note: This point is above the 1.2 ms axis limit, estimated from the line's trajectory).
**2. Batch-invariant (Triton) - Blue Line with Diamonds:**
* **Trend:** The line is flat for a longer range than the Python implementation, then begins a moderate upward curve after 512 tokens.
* **Data Points (Approximate):**
* 1 token: ~0.05 ms
* 8 tokens: ~0.05 ms
* 32 tokens: ~0.05 ms
* 128 tokens: ~0.05 ms
* 256 tokens: ~0.05 ms
* 512 tokens: ~0.05 ms
* 1024 tokens: ~0.08 ms
* 2048 tokens: ~0.12 ms
* 4096 tokens: ~0.20 ms
**3. Non-batch-invariant (CUDA) - Green Line with Circles:**
* **Trend:** This line is the flattest for the longest duration, showing only a very slight upward trend at the highest token counts.
* **Data Points (Approximate):**
* 1 token: ~0.02 ms
* 8 tokens: ~0.02 ms
* 32 tokens: ~0.02 ms
* 128 tokens: ~0.02 ms
* 256 tokens: ~0.02 ms
* 512 tokens: ~0.03 ms
* 1024 tokens: ~0.05 ms
* 2048 tokens: ~0.10 ms
* 4096 tokens: ~0.15 ms
### Key Observations
1. **Performance Hierarchy:** For all token counts shown, the execution time order is consistently: CUDA (fastest) < Triton < Python (slowest).
2. **Scaling Behavior:** The performance gap between implementations widens dramatically as the number of tokens increases. The Python implementation's time cost grows super-linearly (appearing quadratic or exponential), while the CUDA and Triton implementations scale more gently.
3. **Critical Threshold:** A significant performance divergence begins between 256 and 512 tokens. Below this range, the times for all three are relatively stable and close together. Above it, the Python line separates sharply.
4. **Relative Improvement:** At 4096 tokens, the CUDA implementation is approximately 8.7x faster than the Python implementation (1.30 ms / 0.15 ms ≈ 8.7) and about 1.3x faster than the Triton implementation (0.20 ms / 0.15 ms ≈ 1.3).
### Interpretation
This chart illustrates a classic performance comparison between different programming paradigms and hardware backends for a computational task (likely a machine learning operation like attention or a kernel). The data suggests:
* **The "Batch-invariant (Python)" implementation** likely represents a reference or unoptimized implementation. Its poor scaling indicates significant overhead that becomes prohibitive for large inputs, making it unsuitable for production workloads with high token counts.
* **The "Batch-invariant (Triton)" implementation** shows the benefit of using a specialized compiler (Triton) for GPU kernels. It offers a substantial improvement over pure Python, especially at scale, by generating optimized machine code.
* **The "Non-batch-invariant (CUDA)" implementation** represents a hand-tuned, low-level CUDA kernel. Its superior performance, particularly its excellent scaling, highlights the efficiency gains possible with direct hardware programming, though it may come with higher development complexity.
* **The "Batch-invariant" vs. "Non-batch-invariant"** distinction in the labels hints at an algorithmic or implementation constraint. The non-batch-invariant CUDA version's advantage suggests that relaxing this constraint allows for a more efficient computation path.
**In summary, the chart makes a compelling case for using optimized, compiled backends (Triton, CUDA) over interpreted Python for performance-critical operations involving large datasets (high token counts), with hand-optimized CUDA providing the best performance.**