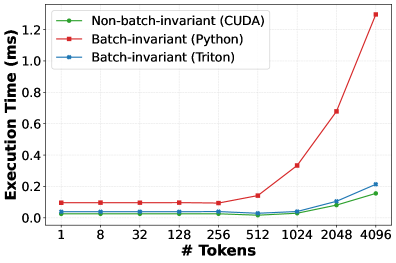
## Line Graph: Execution Time vs. Number of Tokens
### Overview
The image is a line graph comparing the execution time (in milliseconds) of three computational methods across varying numbers of tokens. The x-axis represents the number of tokens (ranging from 1 to 4096), and the y-axis represents execution time (0 to 1.2 ms). Three data series are plotted:
- **Non-batch-invariant (CUDA)** (green line)
- **Batch-invariant (Python)** (red line)
- **Batch-invariant (Triton)** (blue line)
### Components/Axes
- **X-axis (Horizontal)**:
- Label: `# Tokens`
- Values: 1, 8, 32, 128, 256, 512, 1024, 2048, 4096
- Scale: Logarithmic (exponential growth in token counts).
- **Y-axis (Vertical)**:
- Label: `Execution Time (ms)`
- Range: 0.0 to 1.2 ms
- Scale: Linear.
- **Legend**:
- Position: Top-left corner.
- Entries:
- Green: Non-batch-invariant (CUDA)
- Red: Batch-invariant (Python)
- Blue: Batch-invariant (Triton)
### Detailed Analysis
#### Non-batch-invariant (CUDA)
- **Trend**: Flat line, maintaining ~0.0 ms execution time across all token counts.
- **Data Points**:
- 1 token: ~0.0 ms
- 8 tokens: ~0.0 ms
- 32 tokens: ~0.0 ms
- 128 tokens: ~0.0 ms
- 256 tokens: ~0.0 ms
- 512 tokens: ~0.0 ms
- 1024 tokens: ~0.0 ms
- 2048 tokens: ~0.0 ms
- 4096 tokens: ~0.0 ms
#### Batch-invariant (Python)
- **Trend**: Flat until 512 tokens, then steeply increasing.
- **Data Points**:
- 1 token: ~0.1 ms
- 8 tokens: ~0.1 ms
- 32 tokens: ~0.1 ms
- 128 tokens: ~0.1 ms
- 256 tokens: ~0.1 ms
- 512 tokens: ~0.1 ms
- 1024 tokens: ~0.3 ms
- 2048 tokens: ~0.7 ms
- 4096 tokens: ~1.2 ms
#### Batch-invariant (Triton)
- **Trend**: Flat until 512 tokens, then gradual increase.
- **Data Points**:
- 1 token: ~0.05 ms
- 8 tokens: ~0.05 ms
- 32 tokens: ~0.05 ms
- 128 tokens: ~0.05 ms
- 256 tokens: ~0.05 ms
- 512 tokens: ~0.05 ms
- 1024 tokens: ~0.1 ms
- 2048 tokens: ~0.15 ms
- 4096 tokens: ~0.2 ms
### Key Observations
1. **Non-batch-invariant (CUDA)** remains constant at ~0.0 ms, indicating no scaling with token count.
2. **Batch-invariant (Python)** shows a sharp increase in execution time after 512 tokens, reaching ~1.2 ms at 4096 tokens.
3. **Batch-invariant (Triton)** scales more gradually than Python, with execution time rising to ~0.2 ms at 4096 tokens.
4. The red (Python) line diverges significantly from the green (CUDA) and blue (Triton) lines at higher token counts.
### Interpretation
- **Performance Implications**:
- CUDA’s non-batch-invariant approach is highly efficient, maintaining near-zero execution time regardless of token count. This suggests it is optimized for parallel processing or hardware acceleration.
- Python’s batch-invariant method scales poorly, with execution time increasing exponentially as token count grows. This highlights Python’s limitations in handling large-scale computations.
- Triton’s batch-invariant method performs better than Python but still shows some scaling overhead, indicating it is a middle-ground solution.
- **Technical Insights**:
- The stark difference between Python and CUDA suggests that hardware-specific optimizations (e.g., GPU acceleration via CUDA) are critical for high-performance computing.
- Triton’s gradual scaling implies it may balance flexibility and efficiency, though it lags behind CUDA at extreme token counts.
- **Anomalies**:
- The red (Python) line’s sharp rise at 1024 tokens is a notable outlier, indicating a potential bottleneck in Python’s batch processing.
- The green (CUDA) line’s flatness across all token counts is unusual, suggesting a highly optimized or fixed computational pathway.
This data underscores the importance of choosing the right computational framework for tasks involving large token counts, with CUDA emerging as the most efficient option in this scenario.