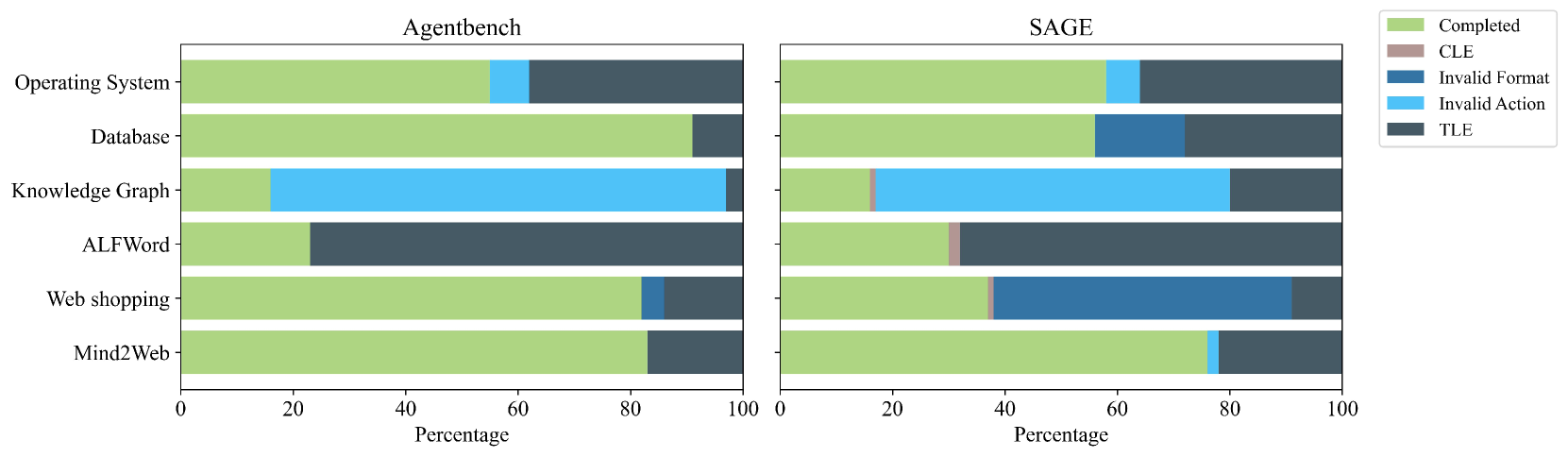
\n
## Horizontal Stacked Bar Chart: Agentbench vs. SAGE Performance Breakdown
### Overview
The image displays two horizontal stacked bar charts side-by-side, comparing the performance breakdown of two systems, "Agentbench" (left panel) and "SAGE" (right panel), across six different tasks. Each bar represents 100% of the outcomes for a task, segmented by color-coded categories indicating the result type (e.g., Completed, various error types). The x-axis for both charts is "Percentage" from 0 to 100.
### Components/Axes
* **Chart Titles:** "Agentbench" (left panel), "SAGE" (right panel).
* **Y-Axis (Tasks):** The same six tasks are listed vertically for both charts, from top to bottom:
1. Operating System
2. Database
3. Knowledge Graph
4. ALFWord
5. Web shopping
6. Mind2Web
* **X-Axis:** Labeled "Percentage" at the bottom of each panel, with major tick marks at 0, 20, 40, 60, 80, and 100.
* **Legend:** Positioned at the top-right of the entire image, outside the chart panels. It defines five categories:
* **Completed** (Light Olive Green)
* **CLE** (Light Brown/Tan)
* **Invalid Format** (Medium Blue)
* **Invalid Action** (Light Blue)
* **TLE** (Dark Grey/Blue)
### Detailed Analysis
**Agentbench (Left Panel):**
* **Operating System:** The bar is dominated by **Completed** (~55%), followed by a small segment of **Invalid Action** (~5%), and a large segment of **TLE** (~40%).
* **Database:** Primarily **Completed** (~90%), with a small **TLE** segment (~10%).
* **Knowledge Graph:** A small **Completed** segment (~15%), a very large **Invalid Action** segment (~80%), and a tiny **TLE** segment (~5%).
* **ALFWord:** A moderate **Completed** segment (~25%) and a very large **TLE** segment (~75%).
* **Web shopping:** A large **Completed** segment (~80%), a small **Invalid Format** segment (~5%), and a moderate **TLE** segment (~15%).
* **Mind2Web:** A large **Completed** segment (~85%) and a moderate **TLE** segment (~15%).
**SAGE (Right Panel):**
* **Operating System:** **Completed** (~60%), a small **Invalid Action** segment (~5%), and a large **TLE** segment (~35%).
* **Database:** **Completed** (~55%), a moderate **Invalid Format** segment (~20%), and a moderate **TLE** segment (~25%).
* **Knowledge Graph:** A small **Completed** segment (~15%), a tiny **CLE** segment (~1%), a very large **Invalid Action** segment (~65%), and a moderate **TLE** segment (~19%).
* **ALFWord:** A moderate **Completed** segment (~30%), a tiny **CLE** segment (~1%), and a very large **TLE** segment (~69%).
* **Web shopping:** A moderate **Completed** segment (~35%), a tiny **CLE** segment (~1%), a very large **Invalid Format** segment (~55%), and a small **TLE** segment (~9%).
* **Mind2Web:** A large **Completed** segment (~75%), a small **Invalid Action** segment (~5%), and a moderate **TLE** segment (~20%).
### Key Observations
1. **Performance Shift:** The "Completed" rate is generally higher or comparable in SAGE for most tasks (Operating System, Knowledge Graph, ALFWord, Mind2Web) but is significantly lower for "Database" and "Web shopping."
2. **Error Type Redistribution:** SAGE shows a dramatic increase in **Invalid Format** errors, especially for "Web shopping" (where it becomes the dominant error) and "Database." Agentbench had almost no Invalid Format errors.
3. **Persistent TLE:** The **TLE** (Time Limit Exceeded?) error remains a major component across most tasks in both systems, particularly for "ALFWord."
4. **New Error Category:** The **CLE** error category appears in SAGE (for Knowledge Graph, ALFWord, Web shopping) but is absent in Agentbench. Its segments are very small.
5. **Task-Specific Profiles:** Each task has a distinct error profile. "Knowledge Graph" is dominated by **Invalid Action** in both systems. "ALFWord" is dominated by **TLE** in both. "Web shopping" shifts from being mostly Completed in Agentbench to having a massive **Invalid Format** problem in SAGE.
### Interpretation
This chart provides a diagnostic breakdown of agent performance beyond simple success rates. It reveals that while SAGE may improve completion rates on some complex reasoning tasks (like Knowledge Graph, ALFWord), it introduces or exacerbates different failure modes, particularly related to output formatting (**Invalid Format**). The near-disappearance of **Invalid Action** in SAGE for "Web shopping" (replaced by **Invalid Format**) suggests a change in how the agent interacts with the environment—perhaps it attempts valid actions but structures its commands incorrectly.
The persistent, large **TLE** segments indicate that computational or step limits are a fundamental bottleneck for both systems on certain tasks. The appearance of **CLE** in SAGE, though minor, points to a new, possibly context-length related, failure mode introduced by the system's architecture.
In essence, the data suggests that SAGE is not uniformly better; it trades one set of error types (like Invalid Action) for another (Invalid Format, CLE), while struggling with the same core limitations (TLE) as Agentbench. This highlights that improving agent robustness requires addressing multiple, distinct failure axes simultaneously.