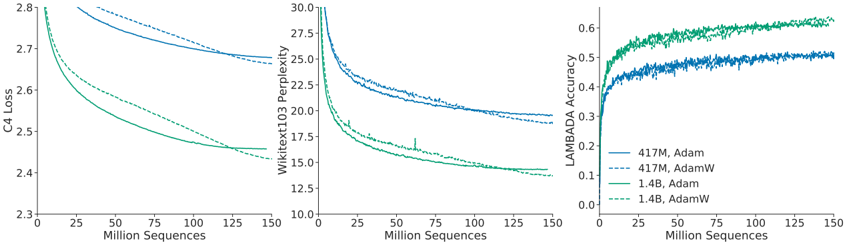
## Line Graphs: Model Performance Across Training Sequences
### Overview
The image contains three line graphs comparing the performance of two model sizes (417M and 1.4B) using Adam and AdamW optimizers across three metrics: C4 Loss, Wikitext103 Perplexity, and LAMBADA Accuracy. Each graph tracks performance as the number of training sequences increases from 0 to 150 million.
### Components/Axes
1. **X-Axis**: "Million Sequences" (0 to 150 million, linear scale).
2. **Y-Axes**:
- Left: "C4 Loss" (2.3 to 2.8).
- Middle: "Wikitext103 Perplexity" (10 to 30).
- Right: "LAMBADA Accuracy" (0 to 0.6).
3. **Legends**:
- **417M Adam**: Solid blue line.
- **417M AdamW**: Dashed blue line.
- **1.4B Adam**: Solid green line.
- **1.4B AdamW**: Dashed green line.
### Detailed Analysis
#### C4 Loss (Left Graph)
- **Trend**: All lines slope downward, indicating decreasing loss with more sequences.
- **417M Adam (solid blue)**: Starts at ~2.8, decreases to ~2.7.
- **417M AdamW (dashed blue)**: Starts at ~2.75, decreases to ~2.6.
- **1.4B Adam (solid green)**: Starts at ~2.7, decreases to ~2.4.
- **1.4B AdamW (dashed green)**: Starts at ~2.65, decreases to ~2.35.
- **Key Insight**: Larger models (1.4B) and AdamW optimizer achieve lower loss.
#### Wikitext103 Perplexity (Middle Graph)
- **Trend**: All lines slope downward, showing reduced perplexity (better performance).
- **417M Adam (solid blue)**: Starts at ~30, decreases to ~25.
- **417M AdamW (dashed blue)**: Starts at ~28, decreases to ~22.
- **1.4B Adam (solid green)**: Starts at ~25, decreases to ~20.
- **1.4B AdamW (dashed green)**: Starts at ~23, decreases to ~18.
- **Key Insight**: Larger models and AdamW optimizer reduce perplexity more effectively.
#### LAMBADA Accuracy (Right Graph)
- **Trend**: All lines slope upward, indicating improved accuracy.
- **417M Adam (solid blue)**: Starts at ~0.3, increases to ~0.5.
- **417M AdamW (dashed blue)**: Starts at ~0.4, increases to ~0.5.
- **1.4B Adam (solid green)**: Starts at ~0.4, increases to ~0.6.
- **1.4B AdamW (dashed green)**: Starts at ~0.5, increases to ~0.6.
- **Key Insight**: Larger models and AdamW optimizer achieve higher accuracy.
### Key Observations
1. **Optimizer Impact**: AdamW consistently outperforms Adam across all metrics and model sizes.
2. **Model Size Impact**: 1.4B models outperform 417M models in all metrics.
3. **Consistency**: Trends are uniform across loss, perplexity, and accuracy, suggesting robust performance improvements.
### Interpretation
The data demonstrates that:
- **AdamW optimizer** enhances training efficiency, leading to lower loss, reduced perplexity, and higher accuracy compared to Adam.
- **Larger models (1.4B)** achieve superior performance, highlighting the benefits of increased capacity.
- The convergence of trends across metrics suggests that both optimizer choice and model size are critical for optimizing language model performance. These findings align with prior research on scaling laws and optimizer efficacy in deep learning.