\n
## Bar Chart & Line Graph: GenPRM as Verifier & Critic
### Overview
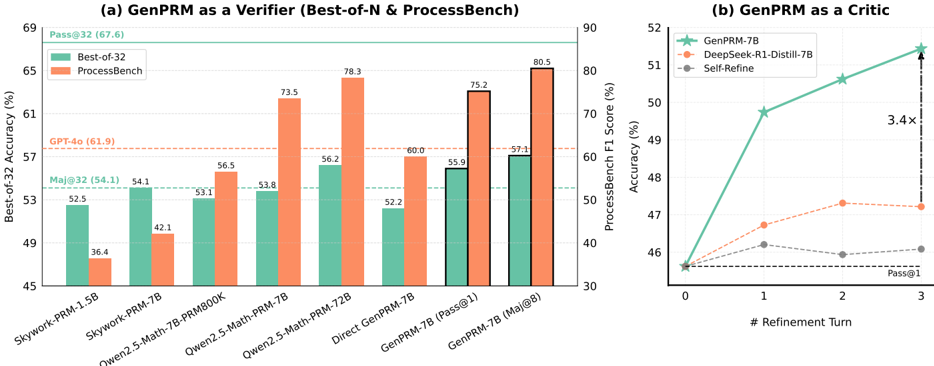
The image presents two charts: a bar chart comparing the "Best-of-32 Accuracy" and "ProcessBench" scores for various models when "GenPRM" is used as a verifier, and a line graph showing the "ProcessBench F1 Score" as a function of "# Refinement Turn" for different models when "GenPRM" is used as a critic.
### Components/Axes
**Chart (a): GenPRM as a Verifier (Best-of-N & ProcessBench)**
* **X-axis:** Model names: Skywork-PRM-1.5B, Skywork-PRM-7B, Owen2.5-Math-7B-PRMBOOK, Owen2.5-Math-PRM-7B, Direct GenPRM-7B, GenPRM-7B [Pass@1], GenPRM-7B [Maj@8].
* **Y-axis:** Best-of-32 Accuracy (%) - Scale from 45 to 69.
* **Legend:**
* Best-of-32 (Teal/Green)
* ProcessBench (Coral/Orange)
* **Annotations:**
* Pass@32 (67.6) - positioned above the first bar.
* GPT-4.0 (61.9) - positioned above the third bar.
* Maj@32 (54.1) - positioned above the fourth bar.
**Chart (b): GenPRM as a Critic**
* **X-axis:** # Refinement Turn - Scale from 0 to 3.
* **Y-axis:** ProcessBench F1 Score (%) - Scale from 30 to 90.
* **Legend:**
* GenPRM-7B (Red)
* DeepSeek-R1-Distill-7B (Green)
* Self-Refine (Blue)
* **Annotations:**
* Pass@1 - positioned near the x-axis.
* 3.4x - positioned near the end of the graph.
### Detailed Analysis or Content Details
**Chart (a): GenPRM as a Verifier**
* **Skywork-PRM-1.5B:** Best-of-32 Accuracy ≈ 36.4%, ProcessBench ≈ 48.8%
* **Skywork-PRM-7B:** Best-of-32 Accuracy ≈ 52.5%, ProcessBench ≈ 54.1%
* **Owen2.5-Math-7B-PRMBOOK:** Best-of-32 Accuracy ≈ 53.1%, ProcessBench ≈ 42.1%
* **Owen2.5-Math-PRM-7B:** Best-of-32 Accuracy ≈ 56.5%, ProcessBench ≈ 53.8%
* **Direct GenPRM-7B:** Best-of-32 Accuracy ≈ 73.5%, ProcessBench ≈ 56.2%
* **GenPRM-7B [Pass@1]:** Best-of-32 Accuracy ≈ 78.3%, ProcessBench ≈ 52.2%
* **GenPRM-7B [Maj@8]:** Best-of-32 Accuracy ≈ 80.5%, ProcessBench ≈ 59.7%
The Best-of-32 accuracy generally increases with the model size and complexity, peaking at GenPRM-7B [Maj@8]. ProcessBench scores are more variable and do not show a consistent trend.
**Chart (b): GenPRM as a Critic**
* **GenPRM-7B:**
* Refinement Turn 0: ≈ 48.2%
* Refinement Turn 1: ≈ 51.1%
* Refinement Turn 2: ≈ 51.8%
* Refinement Turn 3: ≈ 52.1%
* **DeepSeek-R1-Distill-7B:**
* Refinement Turn 0: ≈ 47.5%
* Refinement Turn 1: ≈ 49.2%
* Refinement Turn 2: ≈ 50.5%
* Refinement Turn 3: ≈ 51.1%
* **Self-Refine:**
* Refinement Turn 0: ≈ 46.5%
* Refinement Turn 1: ≈ 48.8%
* Refinement Turn 2: ≈ 50.1%
* Refinement Turn 3: ≈ 50.8%
All three models show an increasing trend in ProcessBench F1 Score with increasing refinement turns, but the improvement plateaus after Refinement Turn 2. GenPRM-7B consistently achieves the highest F1 score across all refinement turns.
### Key Observations
* GenPRM-7B [Maj@8] achieves the highest Best-of-32 accuracy.
* The ProcessBench scores are generally lower than the Best-of-32 accuracy scores.
* GenPRM-7B consistently outperforms DeepSeek-R1-Distill-7B and Self-Refine as a critic, with a 3.4x improvement.
* The improvement in ProcessBench F1 Score diminishes with each refinement turn.
### Interpretation
The data suggests that GenPRM is an effective verifier, particularly when combined with majority voting ([Maj@8]). The increasing Best-of-32 accuracy with more complex models indicates that GenPRM can effectively identify and validate higher-quality outputs.
As a critic, GenPRM demonstrates a positive impact on the ProcessBench F1 Score through iterative refinement. However, the diminishing returns suggest that there is a limit to the benefits of continued refinement. The consistent outperformance of GenPRM-7B over other models highlights its superior ability to guide the refinement process.
The discrepancy between Best-of-32 accuracy and ProcessBench scores could indicate that the two metrics evaluate different aspects of model performance. Best-of-32 accuracy may focus on overall correctness, while ProcessBench F1 Score may be more sensitive to the quality of reasoning or the ability to follow specific instructions. The annotation "Pass@1" and "Pass@32" suggest that the Best-of-32 metric is based on selecting the best output from multiple generations.