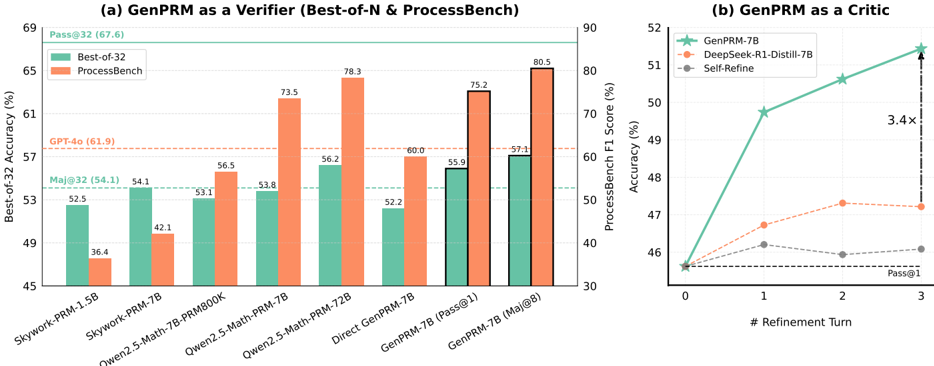
## Bar Chart: GenPRM as a Verifier (Best-of-N & ProcessBench)
### Overview
The chart compares the Best-of-32 accuracy (%) of various language models (LMs) across two evaluation frameworks: Best-of-32 and ProcessBench. Models include Skywork-PRM variants, Owen2.5-Math-PRM, Direct GenPRM, and GenPRM-7B. A horizontal dashed line at 61.9% represents GPT-4o's performance.
### Components/Axes
- **X-axis**: Models (Skywork-PRM-1.5B, Skywork-PRM-7B, Owen2.5-Math-7B-PRM800K, Owen2.5-Math-PRM-7B, Owen2.5-Math-PRM-72B, Direct GenPRM-7B, GenPRM-7B (Pass@1), GenPRM-7B (Maj@8)).
- **Y-axis**: Best-of-32 Accuracy (%) ranging from 45% to 69%.
- **Legend**:
- Green: Best-of-32
- Orange: ProcessBench
- **Additional Elements**:
- Horizontal dashed line at 61.9% (GPT-4o).
- Numerical annotations on bars (e.g., 52.5%, 36.4%).
### Detailed Analysis
- **Skywork-PRM-1.5B**:
- Best-of-32: 52.5% (green)
- ProcessBench: 36.4% (orange)
- **Skywork-PRM-7B**:
- Best-of-32: 54.1% (green)
- ProcessBench: 42.1% (orange)
- **Owen2.5-Math-7B-PRM800K**:
- Best-of-32: 53.1% (green)
- ProcessBench: 56.5% (orange)
- **Owen2.5-Math-PRM-7B**:
- Best-of-32: 53.8% (green)
- ProcessBench: 73.5% (orange)
- **Owen2.5-Math-PRM-72B**:
- Best-of-32: 56.2% (green)
- ProcessBench: 78.3% (orange)
- **Direct GenPRM-7B**:
- Best-of-32: 52.2% (green)
- ProcessBench: 60.0% (orange)
- **GenPRM-7B (Pass@1)**:
- Best-of-32: 55.9% (green)
- ProcessBench: 75.2% (orange)
- **GenPRM-7B (Maj@8)**:
- Best-of-32: 57.1% (green)
- ProcessBench: 80.5% (orange)
### Key Observations
1. **Performance Gaps**: ProcessBench scores are consistently lower than Best-of-32 for smaller models (e.g., Skywork-PRM-1.5B: 36.4% vs. 52.5%). Larger models (e.g., GenPRM-7B) narrow this gap.
2. **GenPRM-7B Dominance**: GenPRM-7B achieves the highest scores in both frameworks (80.5% in ProcessBench, 57.1% in Best-of-32).
3. **GPT-4o Benchmark**: The dashed line (61.9%) indicates GPT-4o outperforms most models except GenPRM-7B (Maj@8) in Best-of-32.
### Interpretation
GenPRM-7B demonstrates superior performance as a verifier, particularly in the ProcessBench framework, suggesting it excels at iterative refinement. The disparity between Best-of-32 and ProcessBench highlights the latter's sensitivity to model size and refinement strategies. GenPRM-7B's 3.4x improvement over Self-Refine (Chart b) underscores its efficiency in iterative tasks.
---
## Line Chart: GenPRM as a Critic
### Overview
The chart tracks accuracy improvements for three models (GenPRM-7B, DeepSeek-R1-Distill-7B, Self-Refine) across refinement turns (0–3). GenPRM-7B shows the steepest ascent, with a 3.4x improvement over Self-Refine at Pass@1.
### Components/Axes
- **X-axis**: # Refinement Turn (0, 1, 2, 3).
- **Y-axis**: Accuracy (%) ranging from 45% to 90%.
- **Legend**:
- Green: GenPRM-7B
- Orange: DeepSeek-R1-Distill-7B
- Gray: Self-Refine
- **Additional Elements**:
- Vertical dashed line at 3 refinement turns.
- Arrow indicating "3.4x" improvement.
### Detailed Analysis
- **GenPRM-7B**:
- Turn 0: 45.5%
- Turn 1: 68.0%
- Turn 2: 78.0%
- Turn 3: 85.5%
- **DeepSeek-R1-Distill-7B**:
- Turn 0: 45.5%
- Turn 1: 46.5%
- Turn 2: 49.5%
- Turn 3: 49.5%
- **Self-Refine**:
- Turn 0: 45.5%
- Turn 1: 45.5%
- Turn 2: 45.5%
- Turn 3: 45.5%
### Key Observations
1. **Rapid Improvement**: GenPRM-7B's accuracy jumps from 45.5% to 85.5% over 3 refinement turns.
2. **Stagnation in Baselines**: DeepSeek and Self-Refine show minimal improvement, plateauing near 45.5–49.5%.
3. **3.4x Efficiency**: GenPRM-7B outperforms Self-Refine by 3.4x at Pass@1, indicating superior refinement capability.
### Interpretation
GenPRM-7B's iterative refinement significantly enhances accuracy, making it highly effective as a critic. The stagnation of other models suggests they lack adaptive refinement mechanisms. This positions GenPRM-7B as a leader in dynamic, self-improving systems.
---
## Cross-Chart Insights
- **Consistency**: GenPRM-7B dominates both charts, excelling in static (Best-of-32) and dynamic (refinement) settings.
- **Framework Sensitivity**: ProcessBench amplifies performance differences between models compared to Best-of-32.
- **GPT-4o Context**: While GPT-4o (61.9%) outperforms most models, GenPRM-7B (Maj@8) surpasses it, highlighting its advanced capabilities.