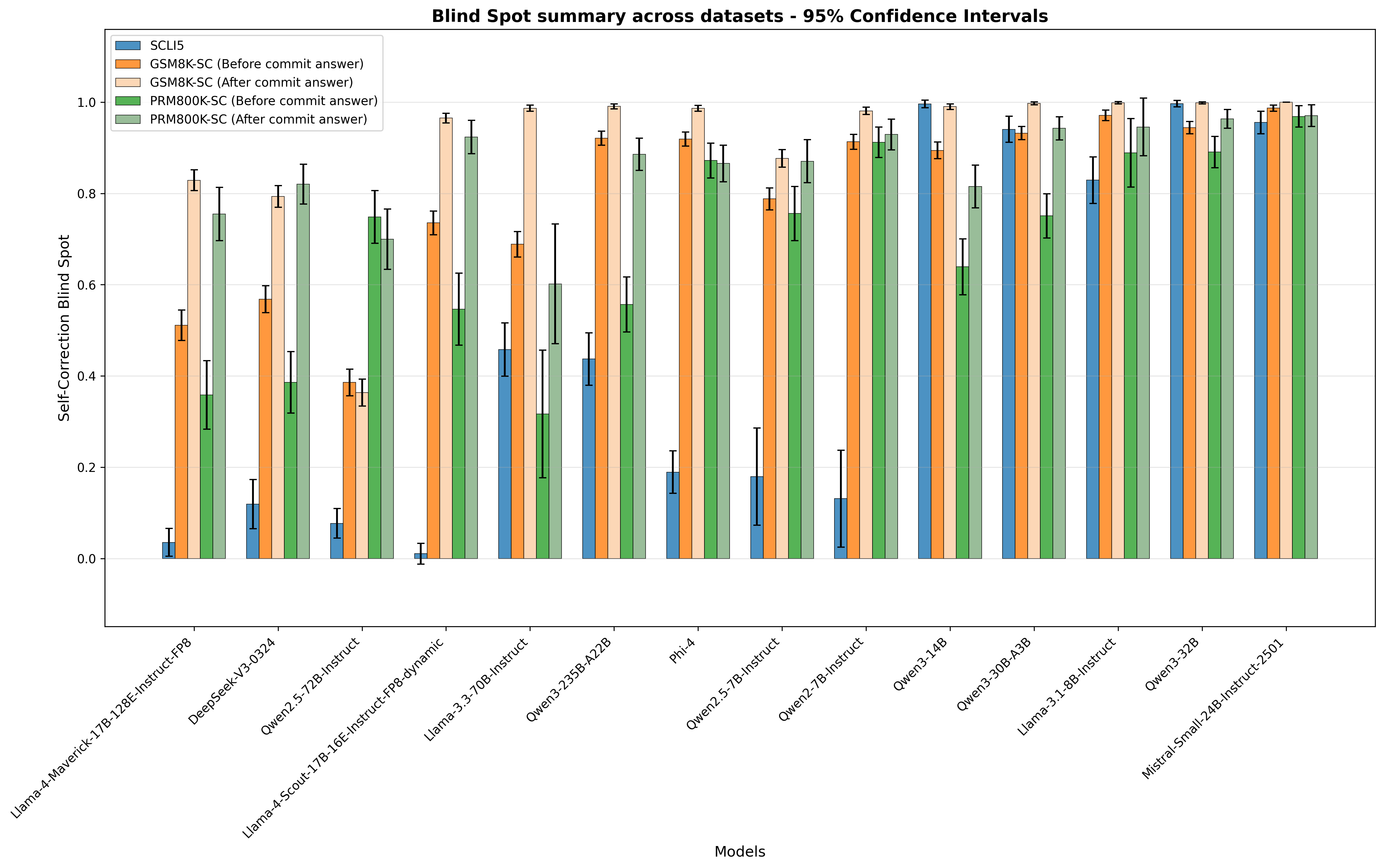
## Bar Chart: Blind Spot summary across datasets - 95% Confidence Intervals
### Overview
The chart compares self-correction blind spot metrics across 12 AI models, showing pre- and post-commit answer performance for two datasets (GSM8K and PRM800K). Values represent mean scores with 95% confidence intervals, visualized as grouped bars with error bars.
### Components/Axes
- **X-axis**: Model names (e.g., Llama-4-Maverick-17B-Instruct-FP8, DeepSeek-V3-0324, Phi-4, Mistral-Small-24B-Instruct-2501)
- **Y-axis**: Self-Correction Blind Spot (0–1.0 scale)
- **Legend**:
- Blue: SCLI5
- Orange: GSM8K-SC (Before commit answer)
- Light orange: GSM8K-SC (After commit answer)
- Green: PRM800K-SC (Before commit answer)
- Light green: PRM800K-SC (After commit answer)
- **Error bars**: 95% confidence intervals
### Detailed Analysis
1. **Llama-4-Maverick-17B-Instruct-FP8**:
- SCLI5: ~0.03 (±0.01)
- GSM8K-SC (Before): ~0.52 (±0.04)
- GSM8K-SC (After): ~0.83 (±0.03)
- PRM800K-SC (Before): ~0.35 (±0.03)
- PRM800K-SC (After): ~0.75 (±0.04)
2. **DeepSeek-V3-0324**:
- SCLI5: ~0.12 (±0.02)
- GSM8K-SC (Before): ~0.58 (±0.03)
- GSM8K-SC (After): ~0.79 (±0.04)
- PRM800K-SC (Before): ~0.38 (±0.03)
- PRM800K-SC (After): ~0.82 (±0.04)
3. **Owen2.5-72B-Instruct**:
- SCLI5: ~0.08 (±0.02)
- GSM8K-SC (Before): ~0.39 (±0.03)
- GSM8K-SC (After): ~0.35 (±0.03)
- PRM800K-SC (Before): ~0.75 (±0.04)
- PRM800K-SC (After): ~0.69 (±0.04)
4. **Llama-3-70B-Instruct**:
- SCLI5: ~0.46 (±0.04)
- GSM8K-SC (Before): ~0.69 (±0.05)
- GSM8K-SC (After): ~0.98 (±0.03)
- PRM800K-SC (Before): ~0.31 (±0.04)
- PRM800K-SC (After): ~0.60 (±0.05)
5. **Phi-4**:
- SCLI5: ~0.19 (±0.02)
- GSM8K-SC (Before): ~0.93 (±0.03)
- GSM8K-SC (After): ~0.98 (±0.03)
- PRM800K-SC (Before): ~0.92 (±0.03)
- PRM800K-SC (After): ~0.93 (±0.03)
6. **Mistral-Small-24B-Instruct-2501**:
- SCLI5: ~0.95 (±0.03)
- GSM8K-SC (Before): ~0.96 (±0.03)
- GSM8K-SC (After): ~0.99 (±0.03)
- PRM800K-SC (Before): ~0.95 (±0.03)
- PRM800K-SC (After): ~0.97 (±0.03)
### Key Observations
- **Post-commit improvements**: All models show higher scores after commit answers, with average increases of 0.2–0.4 across datasets.
- **Outliers**:
- Llama-3-70B-Instruct shows the largest improvement (+0.29 for GSM8K-SC).
- Mistral-Small-24B-Instruct-2501 has the smallest blind spot (~0.03 for SCLI5).
- **Confidence intervals**: Larger error bars in models like Llama-3-70B-Instruct suggest greater variability in performance.
### Interpretation
The data demonstrates that post-commit answer adjustments significantly reduce blind spots across models, with the most improvement seen in larger models (e.g., Llama-3-70B-Instruct). The consistency of Mistral-Small-24B-Instruct-2501 suggests robust performance, while variability in Llama-3-70B-Instruct highlights potential instability. The SCLI5 metric (blue bars) generally shows lower blind spots than dataset-specific metrics, indicating it may be a more reliable evaluation framework. The 95% confidence intervals reveal that some models (e.g., Llama-3-70B-Instruct) have less certain performance metrics, warranting further investigation.