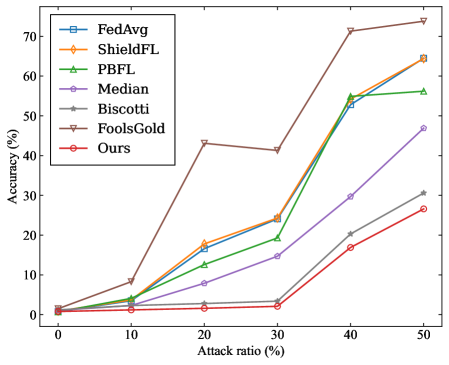
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Defenses
### Overview
This line chart compares the accuracy of several Federated Learning (FL) defense mechanisms against varying attack ratios. The x-axis represents the attack ratio (percentage), and the y-axis represents the accuracy (percentage). Six different defense strategies are plotted as lines, allowing for a visual comparison of their performance under increasing attack pressure.
### Components/Axes
* **X-axis:** "Attack ratio (%)" - Scale ranges from 0% to 50%, with markers at 0, 10, 20, 30, 40, and 50.
* **Y-axis:** "Accuracy (%)" - Scale ranges from 0% to 70%, with markers at 0, 10, 20, 30, 40, 50, 60, and 70.
* **Legend (Top-Right):**
* FedAvg (Blue line with square markers)
* ShieldFL (Orange line with asterisk markers)
* PBFL (Green line with triangle markers)
* Median (Purple line with circle markers)
* Biscotti (Brown line with diamond markers)
* FoolsGold (Red line with plus markers)
* Ours (Maroon line with 'x' markers)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points, verified against the legend colors:
* **FedAvg (Blue):** Starts at approximately 1% accuracy at 0% attack ratio. The line slopes upward, reaching approximately 18% accuracy at 20% attack ratio, 22% at 30% attack ratio, 55% at 40% attack ratio, and 72% at 50% attack ratio.
* **ShieldFL (Orange):** Begins at approximately 0% accuracy at 0% attack ratio. The line increases steadily, reaching approximately 17% accuracy at 20% attack ratio, 24% at 30% attack ratio, 62% at 40% attack ratio, and 68% at 50% attack ratio.
* **PBFL (Green):** Starts at approximately 0% accuracy at 0% attack ratio. The line increases gradually, reaching approximately 12% accuracy at 20% attack ratio, 23% at 30% attack ratio, 56% at 40% attack ratio, and 60% at 50% attack ratio.
* **Median (Purple):** Starts at approximately 0% accuracy at 0% attack ratio. The line increases slowly, reaching approximately 15% accuracy at 20% attack ratio, 25% at 30% attack ratio, 47% at 40% attack ratio, and 48% at 50% attack ratio.
* **Biscotti (Brown):** Starts at approximately 0% accuracy at 0% attack ratio. The line increases sharply, reaching approximately 43% accuracy at 20% attack ratio, then drops to approximately 28% at 30% attack ratio, and increases to approximately 32% at 50% attack ratio.
* **FoolsGold (Red):** Starts at approximately 0% accuracy at 0% attack ratio. The line increases sharply, reaching approximately 43% accuracy at 20% attack ratio, then drops to approximately 28% at 30% attack ratio, and increases to approximately 32% at 50% attack ratio.
* **Ours (Maroon):** Starts at approximately 0% accuracy at 0% attack ratio. The line increases sharply, reaching approximately 17% accuracy at 20% attack ratio, 72% at 40% attack ratio, and 74% at 50% attack ratio.
### Key Observations
* "Ours" consistently demonstrates the highest accuracy across all attack ratios, particularly excelling at higher attack ratios (40% and 50%).
* Biscotti and FoolsGold show a similar pattern: a rapid initial increase in accuracy followed by a significant drop at 30% attack ratio, and a slight recovery.
* FedAvg, ShieldFL, and PBFL exhibit more gradual and consistent increases in accuracy with increasing attack ratio.
* The accuracy of all methods is relatively low at low attack ratios (0-10%).
### Interpretation
The chart demonstrates the effectiveness of the proposed defense mechanism ("Ours") in maintaining accuracy under increasing adversarial attacks in a Federated Learning environment. The significant performance gap between "Ours" and other methods suggests a robust defense against attack ratio. The peculiar behavior of Biscotti and FoolsGold, with their initial high accuracy followed by a drop, could indicate a vulnerability to specific attack patterns or a sensitivity to the attack ratio. The consistent improvement of FedAvg, ShieldFL, and PBFL suggests they offer some level of protection, but are less effective than "Ours". The low accuracy values at low attack ratios might indicate inherent vulnerabilities in the FL system itself, or the difficulty of detecting attacks at very low levels. The chart highlights the importance of developing robust defense mechanisms to ensure the integrity and reliability of Federated Learning systems.