## Heatmap: Layer Importance vs. Parameter
### Overview
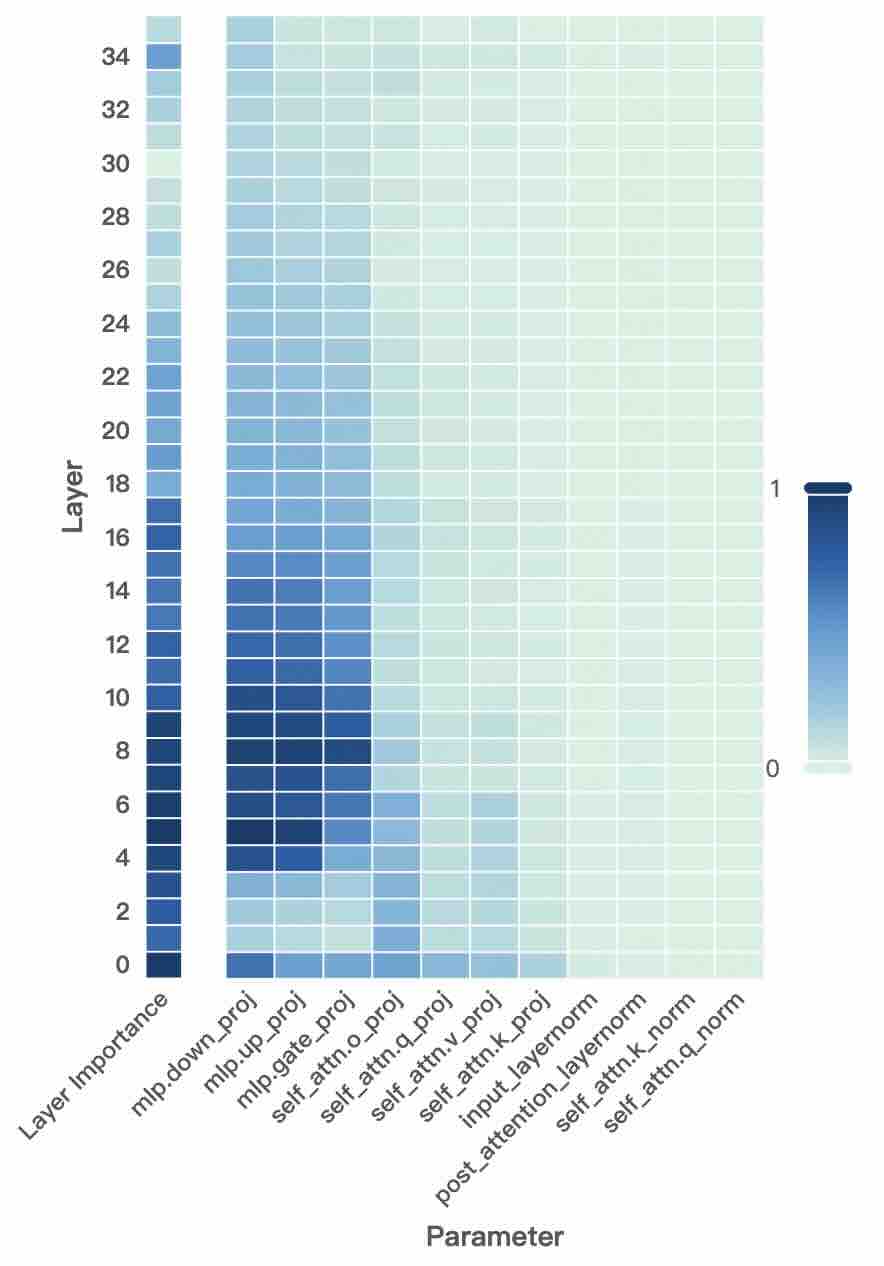
This image presents a heatmap visualizing the relationship between layer number and the importance of different parameters within a model. The heatmap uses a color gradient to represent the magnitude of layer importance, with darker shades indicating higher importance and lighter shades indicating lower importance. The x-axis represents different parameters, and the y-axis represents the layer number. A colorbar on the right indicates the scale, mapping color to importance values from 0 to 1.
### Components/Axes
* **X-axis:** "Parameter" - Categorical variable representing different model parameters. The parameters listed are: `mlp.down_proj`, `mlp.up_proj`, `mlp.gate_o_proj`, `self_attn.q_proj`, `self_attn.v_proj`, `self_attn.k_proj`, `input_layernorm`, `post_attention_layernorm`, `self_attn.norm`, `self_attn.q_norm`.
* **Y-axis:** "Layer" - Numerical variable representing the layer number, ranging from 0 to 34.
* **Colorbar:** Scale from 0 to 1, representing "Layer Importance". Darker blue indicates higher importance, lighter blue indicates lower importance.
* **Legend:** Located on the right side of the heatmap, the colorbar provides a visual key for interpreting the importance values.
### Detailed Analysis
The heatmap displays the layer importance for each parameter across all layers. The color intensity varies significantly depending on the parameter and layer.
Here's a breakdown of the observed trends for each parameter, moving from left to right:
* **mlp.down_proj:** Shows high importance (dark blue) in layers 0-12, then gradually decreases to low importance (light blue) in higher layers.
* **mlp.up_proj:** Similar to `mlp.down_proj`, high importance in layers 0-12, decreasing in higher layers.
* **mlp.gate_o_proj:** High importance in layers 0-10, then a more rapid decrease to low importance.
* **self_attn.q_proj:** Moderate importance across most layers, with a slight increase in layers 16-24.
* **self_attn.v_proj:** Moderate importance across most layers, with a slight increase in layers 16-24.
* **self_attn.k_proj:** Moderate importance across most layers, with a slight increase in layers 16-24.
* **input_layernorm:** Low to moderate importance across all layers, with a slight increase in layers 20-30.
* **post_attention_layernorm:** Low to moderate importance across all layers, with a slight increase in layers 20-30.
* **self_attn.norm:** Low importance across all layers.
* **self_attn.q_norm:** Low importance across all layers.
**Approximate Data Points (based on color intensity and position):**
* `mlp.down_proj` at Layer 6: Importance ≈ 0.9
* `mlp.down_proj` at Layer 20: Importance ≈ 0.3
* `mlp.up_proj` at Layer 6: Importance ≈ 0.85
* `mlp.up_proj` at Layer 20: Importance ≈ 0.25
* `mlp.gate_o_proj` at Layer 6: Importance ≈ 0.9
* `mlp.gate_o_proj` at Layer 20: Importance ≈ 0.1
* `self_attn.q_proj` at Layer 18: Importance ≈ 0.5
* `self_attn.q_proj` at Layer 30: Importance ≈ 0.4
* `input_layernorm` at Layer 25: Importance ≈ 0.4
* `input_layernorm` at Layer 5: Importance ≈ 0.2
### Key Observations
* The `mlp.down_proj`, `mlp.up_proj`, and `mlp.gate_o_proj` parameters exhibit the highest importance in the initial layers (0-12) and then rapidly decrease in importance as the layer number increases.
* The `self_attn` parameters show relatively consistent, moderate importance across most layers.
* The `input_layernorm` and `post_attention_layernorm` parameters have low to moderate importance, with a slight increase in later layers.
* `self_attn.norm` and `self_attn.q_norm` consistently show the lowest importance across all layers.
### Interpretation
The heatmap suggests that the MLP components (`mlp.down_proj`, `mlp.up_proj`, `mlp.gate_o_proj`) are crucial for the initial processing of information in the model, while the self-attention mechanisms (`self_attn` parameters) play a more consistent role throughout the network. The normalization layers (`input_layernorm`, `post_attention_layernorm`) contribute moderately, potentially stabilizing the learning process.
The decreasing importance of the MLP components in higher layers could indicate that the model relies less on these initial transformations as it progresses through deeper layers. The consistent importance of the self-attention mechanisms suggests that they are essential for capturing long-range dependencies and contextual information at all levels of the network.
The low importance of `self_attn.norm` and `self_attn.q_norm` might suggest that these normalization steps are less critical for the performance of the self-attention mechanism in this specific model architecture.
This visualization provides valuable insights into the relative contributions of different parameters and layers, which can be used to guide model optimization, pruning, or further analysis.