## Heatmap: Parameter Importance Across Transformer Layers
### Overview
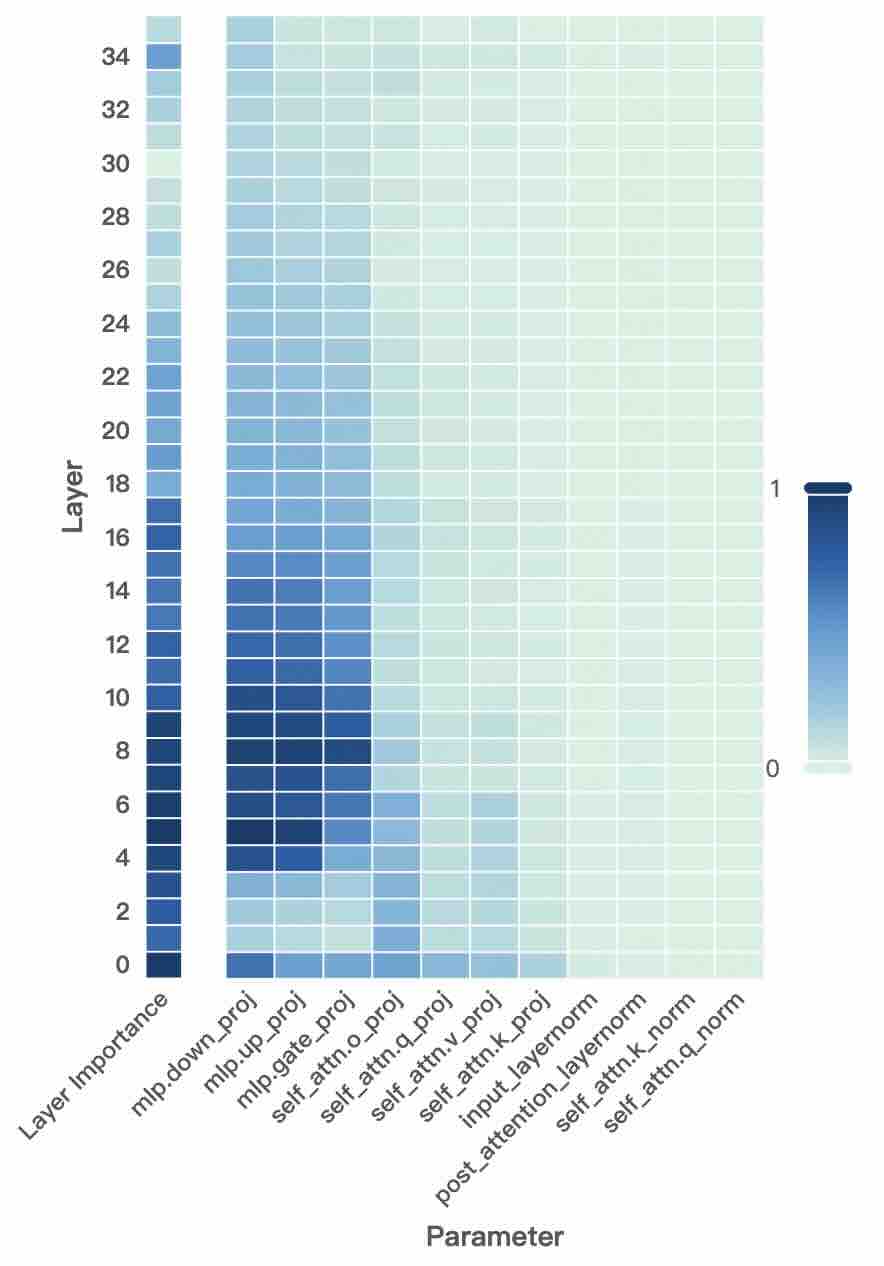
The image is a heatmap visualizing the importance of various parameters across 35 transformer layers (0-34). Darker blue shades represent higher importance values (closer to 1), while lighter shades indicate lower values (closer to 0). The heatmap reveals distinct patterns of parameter significance across different layers.
### Components/Axes
- **Y-axis (Layer)**: Layer numbers from 0 (bottom) to 34 (top), increasing upward.
- **X-axis (Parameter)**: 10 parameters related to transformer architecture:
1. `mlp.down_proj`
2. `mlp.up_proj`
3. `mlp.gate_proj`
4. `mlp.attn.o_proj`
5. `self_attn.q_proj`
6. `self_attn.v_proj`
7. `self_attn.k_proj`
8. `input_attention_layernorm`
9. `self_attn.k_norm`
10. `self_attn.q_norm`
- **Color Scale**: Right-side gradient from 0 (lightest) to 1 (darkest), with numerical labels 0 and 1.
### Detailed Analysis
- **Layer 0-10**:
- `mlp.down_proj` consistently shows the highest values (0.8-0.9).
- `mlp.up_proj` and `mlp.gate_proj` also show strong importance (0.6-0.8).
- `self_attn.q_proj` has moderate-high values (0.6-0.7).
- `self_attn.k_norm` and `self_attn.q_norm` show lower values (0.2-0.4).
- **Layer 10-20**:
- `mlp.down_proj` decreases to 0.6-0.7.
- `mlp.up_proj` and `mlp.gate_proj` drop to 0.4-0.6.
- `self_attn.q_proj` remains stable at 0.5-0.6.
- `input_attention_layernorm` shows moderate values (0.4-0.5).
- **Layer 20-34**:
- All parameters show values <0.5, with most <0.3.
- `mlp.down_proj` and `mlp.up_proj` decline to 0.3-0.4.
- `self_attn.q_proj` decreases to 0.3-0.4.
- `self_attn.k_norm` and `self_attn.q_norm` remain the lowest (0.1-0.2).
### Key Observations
1. **Early Layer Dominance**: Parameters like `mlp.down_proj` and `mlp.up_proj` dominate importance in early layers (0-10), suggesting critical roles in initial feature extraction.
2. **Gradual Decline**: Importance values generally decrease with increasing layer depth, except for `self_attn.q_proj`, which remains relatively stable.
3. **Normalization Parameters**: `self_attn.k_norm` and `self_attn.q_norm` consistently show the lowest importance across all layers.
4. **Projection Parameters**: `mlp.gate_proj` and `mlp.attn.o_proj` show moderate importance in early layers but decline sharply in deeper layers.
### Interpretation
The heatmap suggests that early transformer layers rely heavily on MLP projection parameters (`mlp.down_proj`, `mlp.up_proj`) for processing, while later layers shift toward reduced reliance on these components. The stability of `self_attn.q_proj` across layers indicates its persistent importance in attention mechanisms. The minimal importance of normalization parameters (`self_attn.k_norm`, `self_attn.q_norm`) across all layers implies these components may have less direct impact on model performance compared to projection and attention mechanisms. This pattern aligns with typical transformer architectures where early layers handle feature extraction and later layers focus on higher-level abstractions.