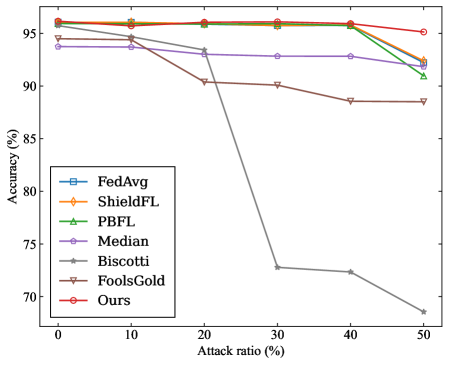
## Line Chart: Accuracy vs. Attack Ratio for Various Federated Learning Methods
### Overview
The chart compares the accuracy retention of seven federated learning methods (FedAvg, ShieldFL, PBFL, Median, Biscotti, FoolsGold, Ours) as the attack ratio increases from 0% to 50%. Accuracy is measured on the y-axis (70–95%), while the x-axis represents attack ratio percentages. The legend on the left maps colors and markers to each method.
### Components/Axes
- **Y-axis**: Accuracy (%) with ticks at 70, 75, 80, 85, 90, 95.
- **X-axis**: Attack ratio (%) with ticks at 0, 10, 20, 30, 40, 50.
- **Legend**: Positioned on the left, with distinct colors and markers for each method:
- FedAvg: Blue square
- ShieldFL: Orange diamond
- PBFL: Green triangle
- Median: Purple pentagon
- Biscotti: Gray star
- FoolsGold: Brown triangle
- Ours: Red circle
### Detailed Analysis
1. **FedAvg (Blue Square)**: Starts at ~95% accuracy at 0% attack ratio, showing a slight decline to ~93% at 50%.
2. **ShieldFL (Orange Diamond)**: Maintains near-constant accuracy (~95%) across all attack ratios.
3. **PBFL (Green Triangle)**: Begins at ~95%, drops sharply to ~90% at 30%, then stabilizes.
4. **Median (Purple Pentagon)**: Remains flat at ~93% accuracy throughout.
5. **Biscotti (Gray Star)**: Starts at ~95%, plummets to ~70% at 30%, then declines further to ~68% at 50%.
6. **FoolsGold (Brown Triangle)**: Declines gradually from ~94% to ~88% over the attack ratio range.
7. **Ours (Red Circle)**: Stays consistently high (~95%) with minimal variation.
### Key Observations
- **Biscotti** exhibits the most drastic performance drop (~25% accuracy loss at 30% attack ratio), suggesting vulnerability to adversarial attacks.
- **ShieldFL** and **Ours** demonstrate the highest robustness, maintaining >94% accuracy even at 50% attack ratio.
- **PBFL** and **FoolsGold** show moderate resilience but degrade significantly after 30% attack ratio.
- **Median** and **FedAvg** exhibit stable but slightly declining trends, indicating moderate robustness.
### Interpretation
The data highlights critical differences in adversarial robustness among federated learning methods. **Biscotti**'s sharp decline suggests it is highly susceptible to attacks, while **ShieldFL** and **Ours** outperform others, potentially due to advanced defense mechanisms. The gradual decline of **FoolsGold** and **PBFL** implies partial mitigation strategies, whereas **Median** and **FedAvg** represent baseline performance. These trends underscore the importance of attack-aware design in federated learning systems, with **Ours** and **ShieldFL** setting a benchmark for resilience. The chart emphasizes trade-offs between model utility and security, guiding future research toward methods that balance both.