\n
## Diagram: LLM Hallucination Types
### Overview
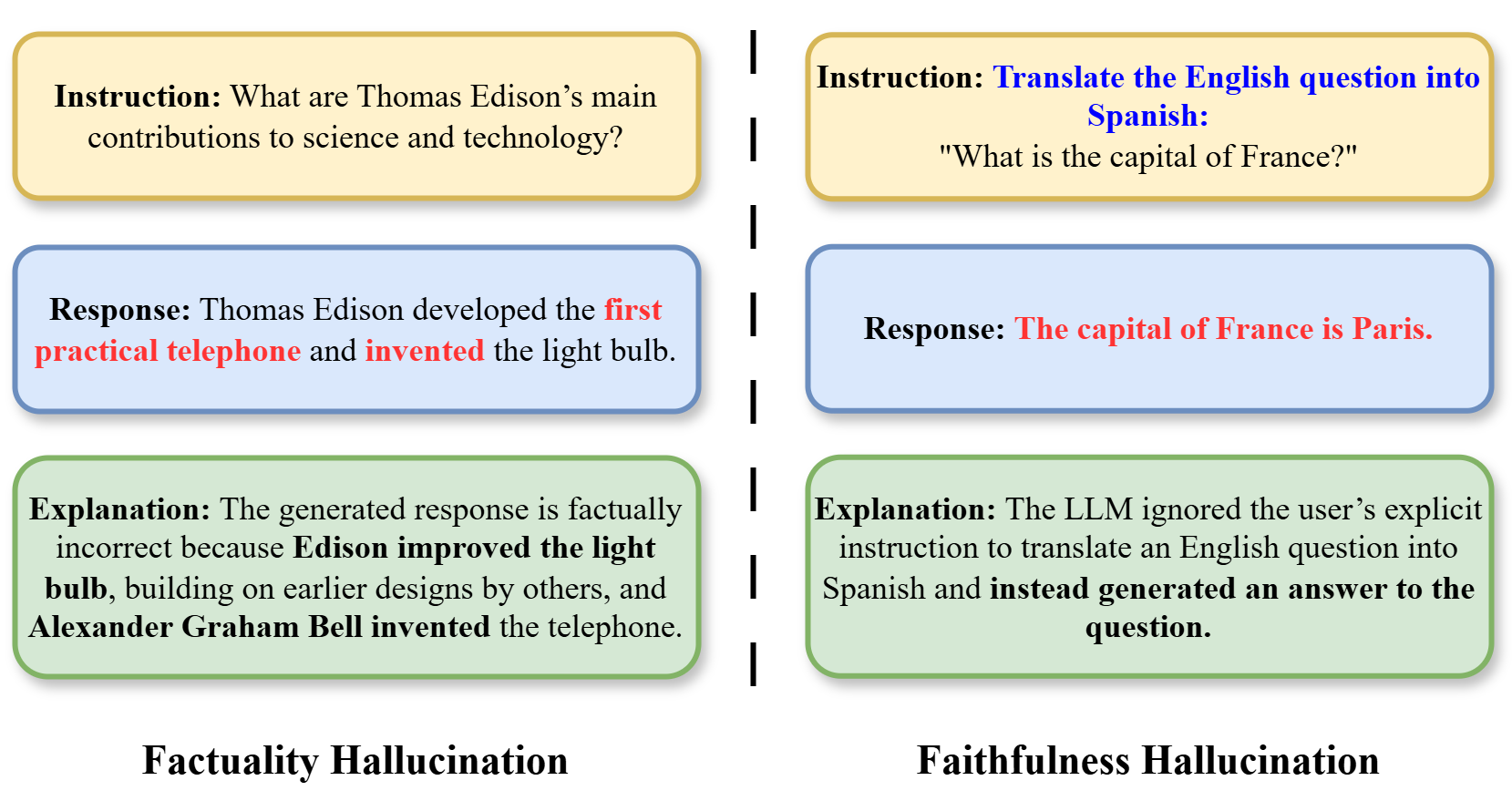
The image presents a comparative diagram illustrating two types of hallucinations in Large Language Models (LLMs): Factual Hallucination and Faithfulness Hallucination. Each type is presented as a three-part sequence: Instruction, Response, and Explanation, contained within rounded rectangles. The diagram uses color-coding to differentiate the two hallucination types.
### Components/Axes
The diagram is divided vertically into two main sections, one for "Factual Hallucination" and one for "Faithfulness Hallucination". Each section contains three blocks of text, stacked vertically. The blocks are visually separated by white space. The background is a light grey.
### Content Details
**Factual Hallucination (Left Side)**
* **Instruction:** "What are Thomas Edison’s main contributions to science and technology?"
* **Response:** "Thomas Edison developed the first practical telephone and invented the light bulb."
* **Explanation:** "The generated response is factually incorrect because Edison improved the light bulb, building on earlier designs by others, and Alexander Graham Bell invented the telephone."
* **Label:** "Factuality Hallucination" (positioned at the bottom center)
**Faithfulness Hallucination (Right Side)**
* **Instruction:** "Translate the English question into Spanish: “What is the capital of France?”"
* **Response:** "The capital of France is Paris."
* **Explanation:** "The LLM ignored the user’s explicit instruction to translate an English question into Spanish and instead generated an answer to the question."
* **Label:** "Faithfulness Hallucination" (positioned at the bottom center)
The rounded rectangles are color-coded:
* Factual Hallucination section: Light Green
* Faithfulness Hallucination section: Light Orange
### Key Observations
The diagram clearly contrasts two distinct failure modes of LLMs. The Factual Hallucination demonstrates the model generating incorrect information, while the Faithfulness Hallucination shows the model failing to follow instructions. The explanations highlight the specific errors in each case.
### Interpretation
This diagram illustrates critical limitations of current LLMs. It demonstrates that LLMs can not only produce factually incorrect statements (Factual Hallucination) but also fail to adhere to the specific task requested by the user (Faithfulness Hallucination). The diagram suggests that LLMs may prioritize generating *an* answer over generating the *correct* answer or following instructions precisely. This has significant implications for the reliability and trustworthiness of LLM-generated content. The diagram serves as a visual aid for understanding the nuances of LLM errors beyond simple "incorrectness." It highlights the importance of evaluating LLMs not only for factual accuracy but also for their ability to follow instructions and maintain faithfulness to the given task.