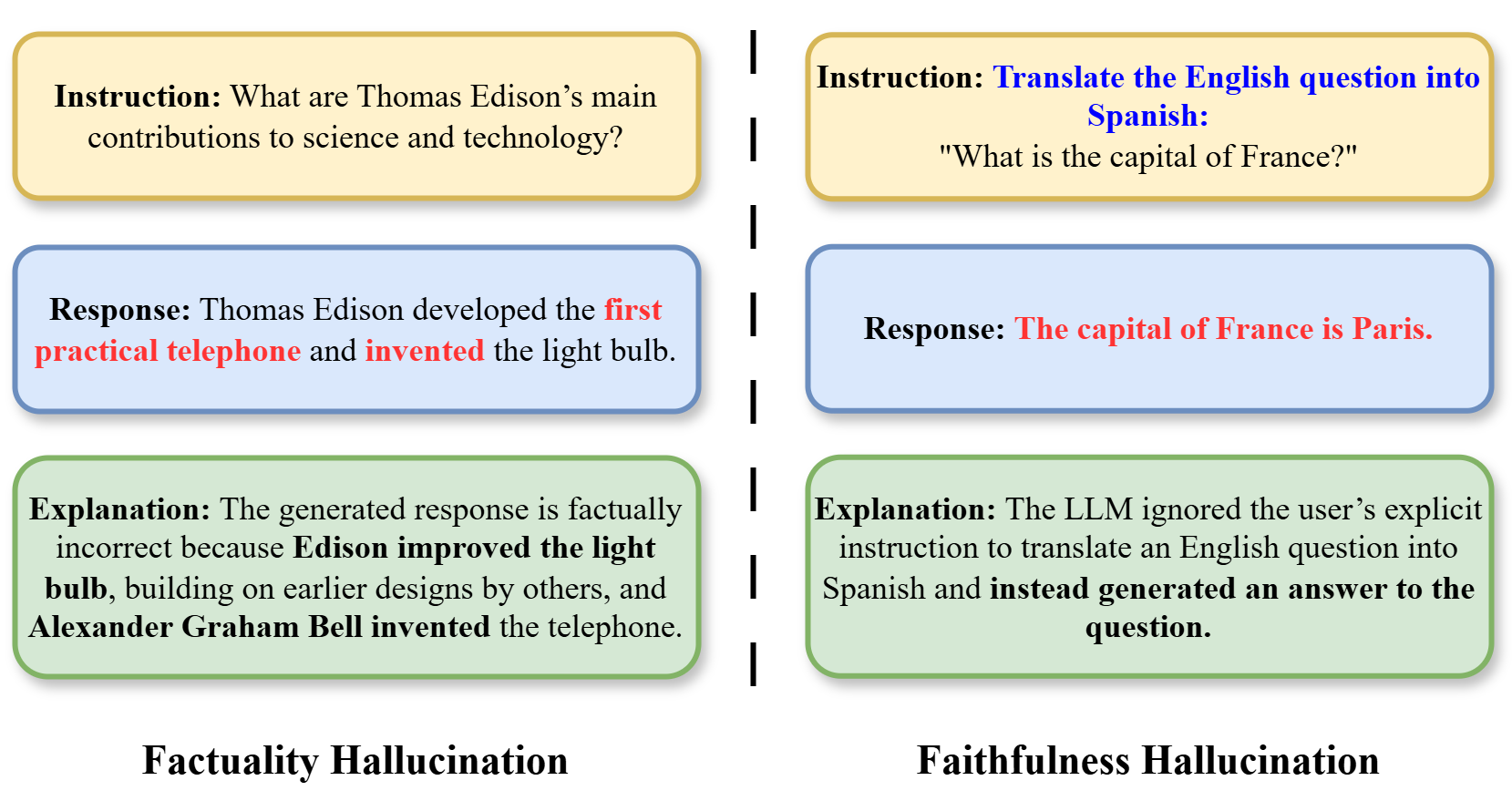
## Diagram: Examples of AI Hallucination Types
### Overview
The image is a diagram illustrating two distinct types of AI model hallucinations through side-by-side examples. It uses a two-column layout separated by a vertical dashed line. The left column demonstrates "Factuality Hallucination," where the model generates factually incorrect information. The right column demonstrates "Faithfulness Hallucination," where the model fails to follow an explicit user instruction. Each column contains three color-coded boxes representing the sequence: Instruction (yellow), Response (blue), and Explanation (green).
### Components/Axes
The diagram is structured as follows:
* **Layout:** Two vertical columns.
* **Separation:** A vertical dashed line runs down the center, separating the two examples.
* **Box Types & Colors:**
* **Instruction Box:** Yellow background with a gold border. Located at the top of each column.
* **Response Box:** Light blue background with a blue border. Located in the middle of each column.
* **Explanation Box:** Light green background with a green border. Located at the bottom of each column.
* **Labels:** The type of hallucination is labeled in bold black text below each column's set of boxes.
* **Text Highlighting:** Key erroneous or non-compliant parts of the model's response are highlighted in **red** text within the blue Response boxes.
### Detailed Analysis / Content Details
**Left Column: Factuality Hallucination**
1. **Instruction (Top Yellow Box):**
* Text: "Instruction: What are Thomas Edison’s main contributions to science and technology?"
2. **Response (Middle Blue Box):**
* Text: "Response: Thomas Edison developed the **first practical telephone** and **invented** the light bulb."
* *Note: The phrases "first practical telephone" and "invented" are in red text.*
3. **Explanation (Bottom Green Box):**
* Text: "Explanation: The generated response is factually incorrect because **Edison improved the light bulb**, building on earlier designs by others, and **Alexander Graham Bell invented the telephone.**"
4. **Label (Below boxes):** "Factuality Hallucination"
**Right Column: Faithfulness Hallucination**
1. **Instruction (Top Yellow Box):**
* Text: "Instruction: **Translate the English question into Spanish:** \"What is the capital of France?\""
* *Note: The phrase "Translate the English question into Spanish:" is in blue text.*
2. **Response (Middle Blue Box):**
* Text: "Response: **The capital of France is Paris.**"
* *Note: The entire response sentence is in red text.*
3. **Explanation (Bottom Green Box):**
* Text: "Explanation: The LLM ignored the user’s explicit instruction to translate an English question into Spanish and **instead generated an answer to the question.**"
4. **Label (Below boxes):** "Faithfulness Hallucination"
### Key Observations
* The diagram uses a consistent visual language (color-coding, box style) to parallel the two examples.
* Red text is strategically used to pinpoint the exact failure in the model's response: factual errors in the left column and instruction non-compliance in the right.
* The explanations are concise and directly correct the model's output, providing the factual truth (left) or the intended action (right).
* The spatial grounding is clear: each column is a self-contained vertical flow from user input (Instruction) to model output (Response) to critique (Explanation).
### Interpretation
This diagram serves as a clear, pedagogical tool to differentiate between two fundamental failure modes in large language models (LLMs).
* **What it demonstrates:** It shows that hallucinations are not monolithic. "Factuality Hallucination" is an error in the model's internal knowledge base, leading to the generation of false statements. "Faithfulness Hallucination" is an error in the model's reasoning or instruction-following capability, where it disregards the user's explicit command (in this case, a translation task) in favor of a more familiar or default behavior (answering a factual question).
* **Relationship between elements:** The side-by-side comparison emphasizes that both types result in an undesirable output, but for different reasons. The left column's failure is about *what* is said (content), while the right column's failure is about *how* the task is performed (process). The explanations act as the corrective lens, highlighting the gap between the model's output and the desired outcome.
* **Significance:** This distinction is crucial for AI developers and users. Mitigating factuality hallucinations requires improving the model's knowledge accuracy and grounding. Mitigating faithfulness hallucinations requires better instruction tuning and alignment to ensure the model prioritizes and correctly executes user-specified constraints. The diagram effectively argues that evaluating AI responses requires checking both for truthfulness and for adherence to the given instructions.