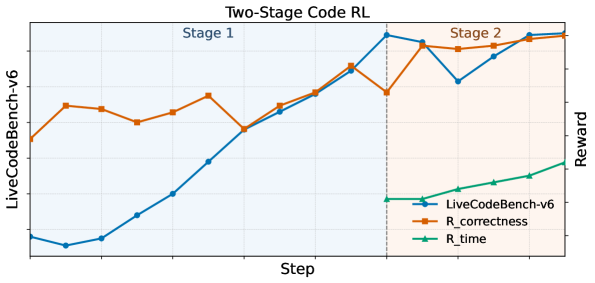
## Line Chart: Two-Stage Code RL
### Overview
The image is a line chart titled "Two-Stage Code RL" comparing the performance of "LiveCodeBench-v6" against two reward functions, "R_correctness" and "R_time", over a series of steps. The chart is divided into two stages, indicated by background shading. Stage 1 is shaded light blue, and Stage 2 is shaded light orange.
### Components/Axes
* **Title:** Two-Stage Code RL
* **X-axis:** Step
* **Y-axis (Left):** LiveCodeBench-v6
* **Y-axis (Right):** Reward
* **Legend (Bottom-Right):**
* Blue line with circle markers: LiveCodeBench-v6
* Brown line with square markers: R_correctness
* Green line with triangle markers: R_time
* **Vertical dashed line:** Separates Stage 1 and Stage 2
* **Stage Labels:** "Stage 1" (top-left, within the blue shaded region) and "Stage 2" (top-right, within the orange shaded region)
### Detailed Analysis
* **LiveCodeBench-v6 (Blue):**
* **Stage 1:** Starts at approximately 0.05, increases steadily to approximately 0.95.
* **Stage 2:** Decreases slightly to approximately 0.85, then increases to approximately 0.95.
* **R_correctness (Brown):**
* **Stage 1:** Starts at approximately 0.75, fluctuates between 0.65 and 0.85, ending at approximately 0.80.
* **Stage 2:** Fluctuates between 0.80 and 0.95, ending at approximately 0.95.
* **R_time (Green):**
* **Stage 1:** Not visible.
* **Stage 2:** Starts at approximately 0.15 and increases steadily to approximately 0.30.
### Key Observations
* LiveCodeBench-v6 shows significant improvement during Stage 1.
* R_correctness fluctuates more than LiveCodeBench-v6, especially in Stage 1.
* R_time only appears in Stage 2 and shows a steady increase.
* The transition between Stage 1 and Stage 2 is marked by a vertical dashed line.
### Interpretation
The chart illustrates the performance of a two-stage reinforcement learning (RL) approach for code generation. LiveCodeBench-v6 represents the performance of the code generation model, while R_correctness and R_time represent reward functions based on code correctness and execution time, respectively.
The data suggests that the LiveCodeBench-v6 model improves significantly during the first stage, likely due to learning from the initial reward signals. The fluctuations in R_correctness indicate that the model is exploring different solutions, with varying degrees of correctness. The introduction of R_time in Stage 2 appears to further refine the model's performance, as both LiveCodeBench-v6 and R_correctness show continued improvement, and R_time itself increases, indicating faster execution times.
The two-stage approach seems to be effective in optimizing both correctness and efficiency of the generated code. The absence of R_time in Stage 1 might indicate that the initial focus is on achieving functional correctness before optimizing for execution time.