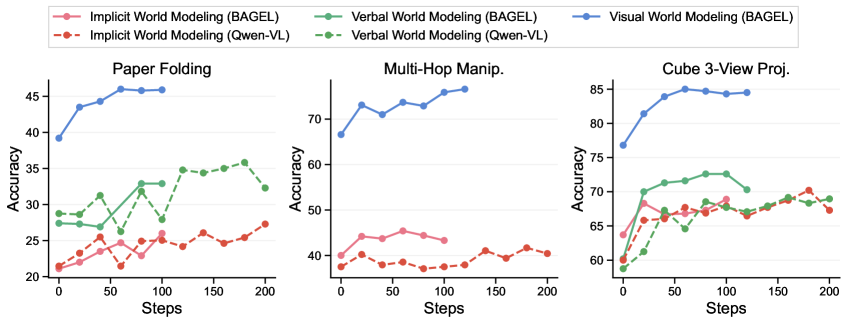
\n
## Line Charts: Performance Comparison of World Modeling Techniques
### Overview
The image presents three separate line charts comparing the performance of different world modeling techniques – Implicit World Modeling (BAGEL & Qwen-VL) and Verbal/Visual World Modeling (BAGEL & Qwen-VL) – across three distinct tasks: Paper Folding, Multi-Hop Manipulation, and Cube 3-View Projection. The performance metric is Accuracy, plotted against the number of Steps.
### Components/Axes
Each chart shares the following components:
* **X-axis:** "Steps" ranging from 0 to 200, with tick marks at intervals of 50.
* **Y-axis:** "Accuracy" ranging from approximately 20 to 85, with tick marks at intervals of 5 or 10.
* **Legend:** Located at the top of the image, spanning all three charts. The legend identifies the data series using both color and label:
* Red (solid line): Implicit World Modeling (BAGEL)
* Orange (dashed line): Implicit World Modeling (Qwen-VL)
* Green (solid line): Verbal World Modeling (BAGEL)
* Teal (dashed line): Verbal World Modeling (Qwen-VL)
* Blue (solid line): Visual World Modeling (BAGEL)
Each chart also has a title indicating the specific task being evaluated:
* "Paper Folding"
* "Multi-Hop Manip." (Multi-Hop Manipulation)
* "Cube 3-View Proj." (Cube 3-View Projection)
### Detailed Analysis or Content Details
**1. Paper Folding Chart:**
* **Blue Line (Visual World Modeling - BAGEL):** Starts at approximately 42 accuracy at 0 steps, increases to around 47 accuracy at 50 steps, plateaus around 47-48 accuracy for the remainder of the steps.
* **Green Line (Verbal World Modeling - BAGEL):** Starts at approximately 32 accuracy at 0 steps, fluctuates between 32 and 36 accuracy for the first 100 steps, then increases to around 38 accuracy at 200 steps.
* **Red Line (Implicit World Modeling - BAGEL):** Starts at approximately 26 accuracy at 0 steps, decreases to around 23 accuracy at 50 steps, then increases to around 28 accuracy at 200 steps.
* **Orange Line (Implicit World Modeling - Qwen-VL):** Starts at approximately 24 accuracy at 0 steps, fluctuates between 24 and 28 accuracy throughout the steps.
**2. Multi-Hop Manipulation Chart:**
* **Blue Line (Visual World Modeling - BAGEL):** Starts at approximately 72 accuracy at 0 steps, increases to around 74 accuracy at 50 steps, and remains relatively stable around 73-74 accuracy for the rest of the steps.
* **Green Line (Verbal World Modeling - BAGEL):** Starts at approximately 42 accuracy at 0 steps, increases to around 46 accuracy at 50 steps, and remains relatively stable around 44-46 accuracy for the rest of the steps.
* **Red Line (Implicit World Modeling - BAGEL):** Starts at approximately 26 accuracy at 0 steps, increases to around 28 accuracy at 50 steps, and remains relatively stable around 26-28 accuracy for the rest of the steps.
* **Orange Line (Implicit World Modeling - Qwen-VL):** Starts at approximately 41 accuracy at 0 steps, decreases to around 39 accuracy at 50 steps, and remains relatively stable around 40-42 accuracy for the rest of the steps.
**3. Cube 3-View Projection Chart:**
* **Blue Line (Visual World Modeling - BAGEL):** Starts at approximately 83 accuracy at 0 steps, increases to around 85 accuracy at 50 steps, and remains relatively stable around 84-85 accuracy for the rest of the steps.
* **Green Line (Verbal World Modeling - BAGEL):** Starts at approximately 72 accuracy at 0 steps, increases to around 75 accuracy at 50 steps, and remains relatively stable around 72-75 accuracy for the rest of the steps.
* **Red Line (Implicit World Modeling - BAGEL):** Starts at approximately 64 accuracy at 0 steps, increases to around 68 accuracy at 50 steps, and remains relatively stable around 68-70 accuracy for the rest of the steps.
* **Orange Line (Implicit World Modeling - Qwen-VL):** Starts at approximately 62 accuracy at 0 steps, increases to around 66 accuracy at 50 steps, and remains relatively stable around 66-68 accuracy for the rest of the steps.
### Key Observations
* Visual World Modeling (BAGEL) consistently outperforms other methods across all three tasks, achieving the highest accuracy and demonstrating the most stable performance.
* Implicit World Modeling (both BAGEL and Qwen-VL) generally exhibits the lowest accuracy across all tasks.
* The performance of Verbal World Modeling (BAGEL and Qwen-VL) falls between Visual and Implicit World Modeling.
* In all three charts, the accuracy tends to plateau after approximately 50-100 steps, indicating diminishing returns with increased steps.
### Interpretation
The data suggests that Visual World Modeling (using BAGEL) is the most effective technique for these three tasks – Paper Folding, Multi-Hop Manipulation, and Cube 3-View Projection. This could be because these tasks heavily rely on spatial reasoning and visual understanding, which Visual World Modeling is specifically designed to handle.
The lower performance of Implicit World Modeling suggests that relying solely on implicit representations of the world may be insufficient for these tasks. The intermediate performance of Verbal World Modeling indicates that incorporating verbal information can improve performance compared to implicit modeling, but it still falls short of the capabilities of visual modeling.
The plateauing of accuracy with increasing steps suggests that the models reach a point of diminishing returns, where further training does not significantly improve performance. This could be due to limitations in the model architecture, the training data, or the inherent complexity of the tasks. The differences in performance between BAGEL and Qwen-VL within each modeling type are relatively small, suggesting that the core modeling approach is more important than the specific implementation details in this case.