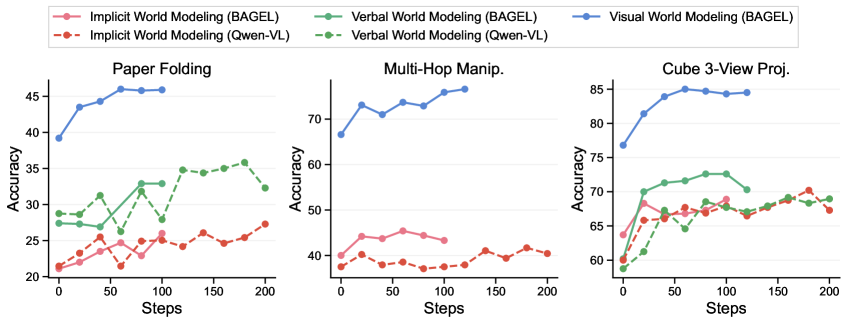
## Line Graphs: Comparative Accuracy of World Modeling Approaches Across Tasks
### Overview
The image contains three line graphs comparing the accuracy of different world modeling approaches (BAGEL and Qwen-VL) across three tasks: **Paper Folding**, **Multi-Hop Manipulation**, and **Cube 3-View Projection**. Each graph tracks accuracy (%) over 200 steps, with distinct lines for **Implicit**, **Verbal**, and **Visual World Modeling** for both BAGEL and Qwen-VL. The graphs highlight performance trends, with BAGEL's Visual World Modeling consistently outperforming Qwen-VL's Verbal World Modeling.
---
### Components/Axes
- **X-axis**: Steps (0–200), labeled "Steps".
- **Y-axis**: Accuracy (%), labeled "Accuracy".
- **Legends**: Positioned at the top of the image, with the following entries:
- **Implicit World Modeling (BAGEL)**: Pink solid line.
- **Implicit World Modeling (Qwen-VL)**: Red dashed line.
- **Verbal World Modeling (BAGEL)**: Green solid line.
- **Verbal World Modeling (Qwen-VL)**: Green dashed line.
- **Visual World Modeling (BAGEL)**: Blue solid line.
- **Graphs**: Three separate line graphs, each corresponding to a task.
---
### Detailed Analysis
#### Paper Folding
- **BAGEL Visual World Modeling (blue)**: Starts at ~40% accuracy, peaks at ~45% by ~50 steps, then stabilizes.
- **Qwen-VL Verbal World Modeling (green dashed)**: Begins at ~25%, rises to ~35% by ~100 steps, then declines to ~30% by 200 steps.
- **Qwen-VL Implicit World Modeling (red dashed)**: Remains low (~20–25%) throughout, with minor fluctuations.
- **BAGEL Implicit World Modeling (pink solid)**: Starts at ~20%, peaks at ~25% by ~100 steps, then stabilizes.
#### Multi-Hop Manipulation
- **BAGEL Visual World Modeling (blue)**: Starts at ~60%, rises to ~70% by ~50 steps, then fluctuates between ~65–70%.
- **Qwen-VL Verbal World Modeling (green dashed)**: Begins at ~40%, peaks at ~50% by ~50 steps, then declines to ~40% by 200 steps.
- **Qwen-VL Implicit World Modeling (red dashed)**: Remains low (~20–25%) throughout, with minor fluctuations.
- **BAGEL Implicit World Modeling (pink solid)**: Starts at ~40%, peaks at ~50% by ~50 steps, then stabilizes.
#### Cube 3-View Projection
- **BAGEL Visual World Modeling (blue)**: Starts at ~75%, rises to ~85% by ~50 steps, then stabilizes.
- **Qwen-VL Verbal World Modeling (green dashed)**: Begins at ~60%, rises to ~70% by ~50 steps, then fluctuates between ~65–70%.
- **Qwen-VL Implicit World Modeling (red dashed)**: Remains low (~60–65%) throughout, with minor fluctuations.
- **BAGEL Implicit World Modeling (pink solid)**: Starts at ~60%, peaks at ~70% by ~50 steps, then stabilizes.
---
### Key Observations
1. **BAGEL's Visual World Modeling** consistently outperforms all other approaches across all tasks, achieving the highest accuracy and stability.
2. **Qwen-VL's Verbal World Modeling** shows moderate performance but lags behind BAGEL's Visual in all tasks.
3. **Implicit World Modeling** (both BAGEL and Qwen-VL) underperforms significantly, with minimal improvement over steps.
4. **Qwen-VL's Verbal World Modeling** exhibits higher variability compared to BAGEL's models, with sharper declines in later steps.
---
### Interpretation
The data suggests that **BAGEL's Visual World Modeling** is the most effective approach for the tested tasks, likely due to its ability to handle visual-spatial reasoning more effectively. Qwen-VL's Verbal World Modeling, while better