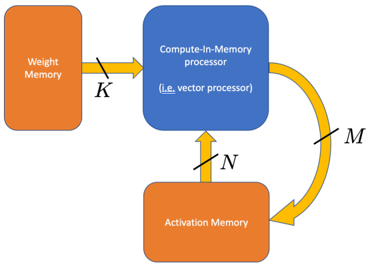
## Diagram: Compute-In-Memory Processor Architecture
### Overview
The image presents a block diagram illustrating the architecture of a Compute-In-Memory processor. It shows the flow of data between Weight Memory, the Compute-In-Memory processor, and Activation Memory.
### Components/Axes
* **Weight Memory:** An orange rectangular block on the left, labeled "Weight Memory".
* **Compute-In-Memory processor:** A blue rounded rectangular block in the center, labeled "Compute-In-Memory processor" and "(i.e. vector processor)".
* **Activation Memory:** An orange rounded rectangular block at the bottom, labeled "Activation Memory".
* **Arrows:**
* A black line labeled "K" connects Weight Memory to the Compute-In-Memory processor.
* A black line labeled "N" connects Activation Memory to the Compute-In-Memory processor.
* A curved yellow arrow labeled "M" connects the Compute-In-Memory processor to Activation Memory.
### Detailed Analysis or ### Content Details
The diagram illustrates the data flow in a Compute-In-Memory architecture. Weight data is fetched from the Weight Memory to the Compute-In-Memory processor (indicated by arrow K). Activation data is fetched from the Activation Memory to the Compute-In-Memory processor (indicated by arrow N). The results of the computation are then written back to the Activation Memory (indicated by arrow M).
### Key Observations
* The diagram highlights the central role of the Compute-In-Memory processor in performing computations directly within the memory.
* The use of separate Weight and Activation Memories suggests a separation of concerns for storing weights and intermediate activation values.
* The feedback loop from the Compute-In-Memory processor to the Activation Memory indicates that the architecture supports iterative computations.
### Interpretation
The diagram illustrates a typical architecture for Compute-In-Memory processing, where computations are performed directly within the memory units. This approach can potentially reduce data movement and improve energy efficiency compared to traditional processor architectures. The separation of weight and activation data, along with the feedback loop, suggests that this architecture is suitable for applications such as deep learning, where iterative computations and large amounts of data are common. The labels K, N, and M likely represent data transfer rates or sizes.