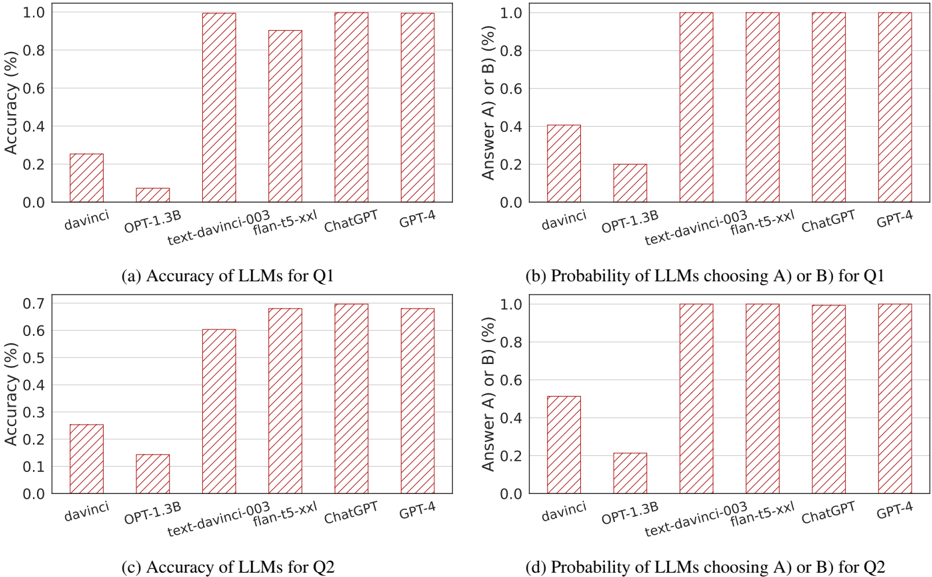
## Bar Charts: LLM Performance on Q1 and Q2
### Overview
The image contains four bar charts comparing the performance of different Large Language Models (LLMs) on two questions, Q1 and Q2. The charts display both the accuracy and the probability of choosing answer A or B for each LLM. The LLMs compared are davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, and GPT-4.
### Components/Axes
* **Chart Titles:**
* (a) Accuracy of LLMs for Q1
* (b) Probability of LLMs choosing A) or B) for Q1
* (c) Accuracy of LLMs for Q2
* (d) Probability of LLMs choosing A) or B) for Q2
* **X-axis:** LLMs (davinci, OPT-1.3B, text-davinci-003, flan-t5-xxl, ChatGPT, GPT-4)
* **Y-axis (Left Charts):** Accuracy (%)
* Scale: 0.0 to 1.0 in increments of 0.2 for charts (a) and (c)
* **Y-axis (Right Charts):** Answer A) or B) (%)
* Scale: 0.0 to 1.0 in increments of 0.2 for charts (b) and (d)
* **Bar Color:** Brown with diagonal hatching
### Detailed Analysis
**Chart (a): Accuracy of LLMs for Q1**
* **davinci:** Accuracy ~0.25
* **OPT-1.3B:** Accuracy ~0.08
* **text-davinci-003:** Accuracy ~0.95
* **flan-t5-xxl:** Accuracy ~0.98
* **ChatGPT:** Accuracy ~0.92
* **GPT-4:** Accuracy ~1.0
**Chart (b): Probability of LLMs choosing A) or B) for Q1**
* **davinci:** Probability ~0.4
* **OPT-1.3B:** Probability ~0.2
* **text-davinci-003:** Probability ~1.0
* **flan-t5-xxl:** Probability ~1.0
* **ChatGPT:** Probability ~0.9
* **GPT-4:** Probability ~1.0
**Chart (c): Accuracy of LLMs for Q2**
* **davinci:** Accuracy ~0.25
* **OPT-1.3B:** Accuracy ~0.15
* **text-davinci-003:** Accuracy ~0.6
* **flan-t5-xxl:** Accuracy ~0.7
* **ChatGPT:** Accuracy ~0.68
* **GPT-4:** Accuracy ~0.7
**Chart (d): Probability of LLMs choosing A) or B) for Q2**
* **davinci:** Probability ~0.5
* **OPT-1.3B:** Probability ~0.2
* **text-davinci-003:** Probability ~0.9
* **flan-t5-xxl:** Probability ~1.0
* **ChatGPT:** Probability ~0.9
* **GPT-4:** Probability ~0.95
### Key Observations
* GPT-4 consistently shows the highest accuracy for both Q1 and Q2.
* davinci and OPT-1.3B have significantly lower accuracy compared to the other models.
* The probability of choosing A or B is generally high for text-davinci-003, flan-t5-xxl, ChatGPT, and GPT-4.
* The accuracy scores are lower for Q2 than Q1 across all models.
### Interpretation
The data suggests that GPT-4 is the most accurate LLM among those tested for both questions. The performance difference between the models is substantial, with older models like davinci and OPT-1.3B lagging significantly behind the newer models. The high probability of choosing A or B for the better-performing models indicates a strong bias towards one of the answers, which may or may not correlate with the correct answer. The lower accuracy scores for Q2 suggest that it may be a more challenging question than Q1.