## Diagram: Vanilla GRPO vs. Training-free GRPO
### Overview
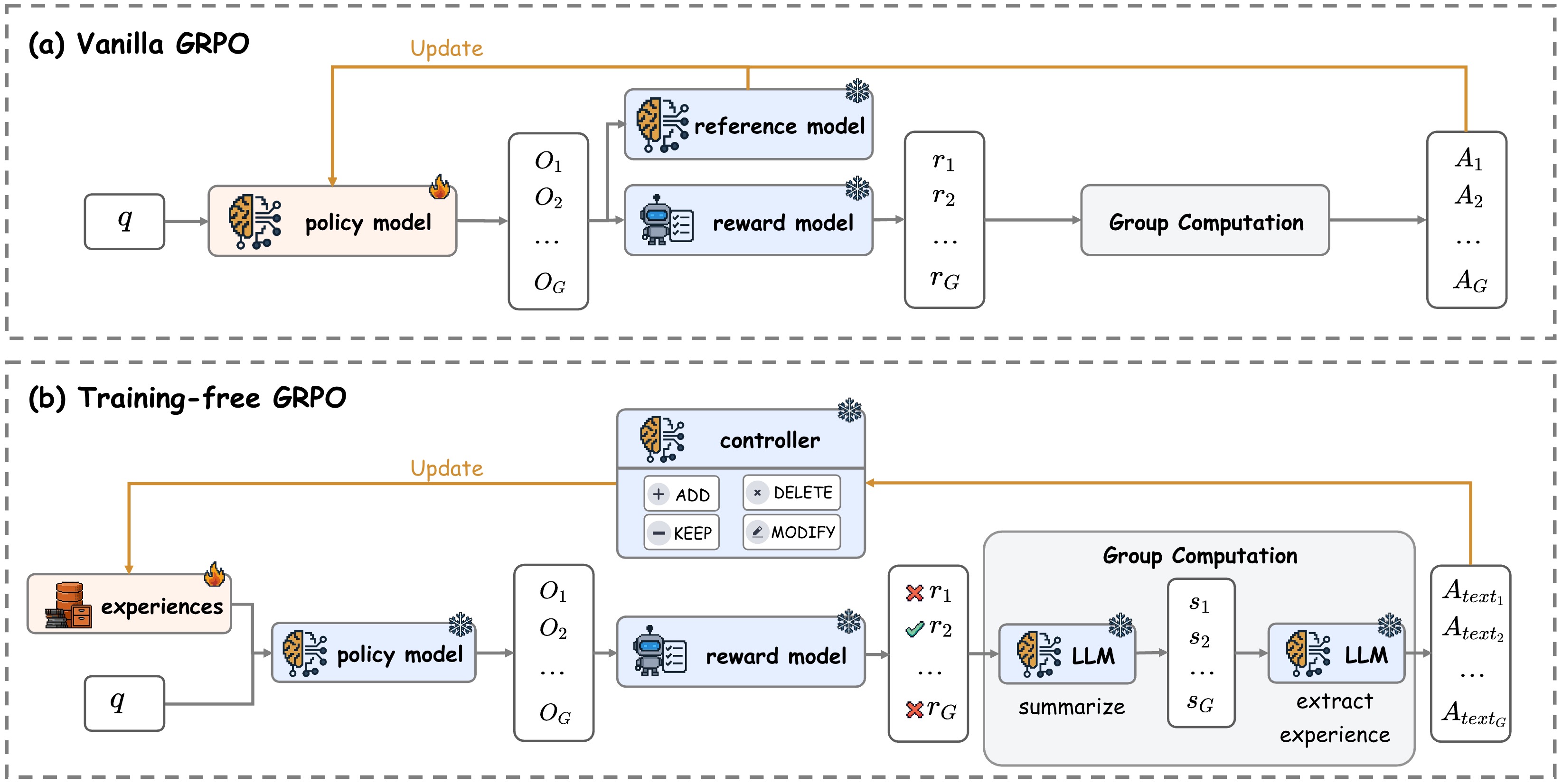
The image presents two diagrams illustrating different approaches to Group Reward Policy Optimization (GRPO): Vanilla GRPO and Training-free GRPO. Both diagrams depict a flow of information and processes, but they differ in their components and how they handle experiences and rewards.
### Components/Axes
**Diagram (a): Vanilla GRPO**
* **Title:** (a) Vanilla GRPO
* **Input:** `q` (unspecified meaning)
* **Policy Model:** A neural network icon labeled "policy model".
* **Observations:** A list of observations `O1`, `O2`, ..., `OG`.
* **Reference Model:** A neural network icon labeled "reference model".
* **Reward Model:** A robot icon labeled "reward model".
* **Rewards:** A list of rewards `r1`, `r2`, ..., `rG`.
* **Group Computation:** A rectangular box labeled "Group Computation".
* **Actions:** A list of actions `A1`, `A2`, ..., `AG`.
* **Update:** An orange arrow labeled "Update" going from the actions `AG` back to the policy model.
**Diagram (b): Training-free GRPO**
* **Title:** (b) Training-free GRPO
* **Experiences:** A stack of books icon labeled "experiences".
* **Input:** `q` (unspecified meaning)
* **Policy Model:** A neural network icon labeled "policy model".
* **Observations:** A list of observations `O1`, `O2`, ..., `OG`.
* **Controller:** A neural network icon labeled "controller" with buttons labeled "+ ADD", "x DELETE", "- KEEP", and "/ MODIFY".
* **Reward Model:** A robot icon labeled "reward model".
* **Rewards:** A list of rewards `r1`, `r2`, ..., `rG`.
* **Group Computation:** A larger rectangular box labeled "Group Computation" containing two neural network icons labeled "LLM" (Large Language Model). The first LLM is labeled "summarize", and the second is labeled "extract experience". The output of the first LLM is `s1`, `s2`, ..., `sG`.
* **Actions:** A list of actions `Atext1`, `Atext2`, ..., `AtextG`.
* **Update:** An orange arrow labeled "Update" going from the actions `AtextG` back to the controller.
### Detailed Analysis or Content Details
**Vanilla GRPO (a):**
1. The input `q` feeds into the "policy model".
2. The "policy model" generates observations `O1` to `OG`.
3. The observations feed into both the "reference model" and the "reward model".
4. The "reference model" and "reward model" generate rewards `r1` to `rG`.
5. The rewards are processed by "Group Computation" to produce actions `A1` to `AG`.
6. The actions `AG` are used to update the "policy model".
**Training-free GRPO (b):**
1. "Experiences" and input `q` feed into the "policy model".
2. The "policy model" generates observations `O1` to `OG`.
3. The observations feed into the "reward model".
4. The "reward model" generates rewards `r1` to `rG`.
5. The rewards are processed by "Group Computation", which involves summarizing with an LLM and extracting experience with another LLM, to produce actions `Atext1` to `AtextG`.
6. The actions `AtextG` are used to update the "controller".
### Key Observations
* Vanilla GRPO directly updates the policy model based on the actions.
* Training-free GRPO introduces a "controller" and uses LLMs for group computation.
* Training-free GRPO uses "experiences" as an input, which are not present in Vanilla GRPO.
* The actions in Vanilla GRPO are denoted as `A1` to `AG`, while in Training-free GRPO, they are denoted as `Atext1` to `AtextG`, suggesting they might be text-based actions.
### Interpretation
The diagrams illustrate two different approaches to GRPO. Vanilla GRPO represents a more traditional approach where the policy model is directly updated based on the rewards and actions. Training-free GRPO introduces a controller and leverages LLMs to process the rewards and extract experiences, potentially allowing for more sophisticated and adaptable behavior. The "training-free" aspect suggests that the LLMs might be pre-trained and not specifically trained for this task, enabling the system to leverage existing knowledge. The controller likely manages the LLMs and the overall process, allowing for more flexible and controlled behavior. The use of "experiences" as an input in the training-free version suggests that it can learn from past interactions, which is not explicitly present in the vanilla version.