## Diagram: Group Reciprocal Proximal Optimization (GRPO) Architectures
### Overview
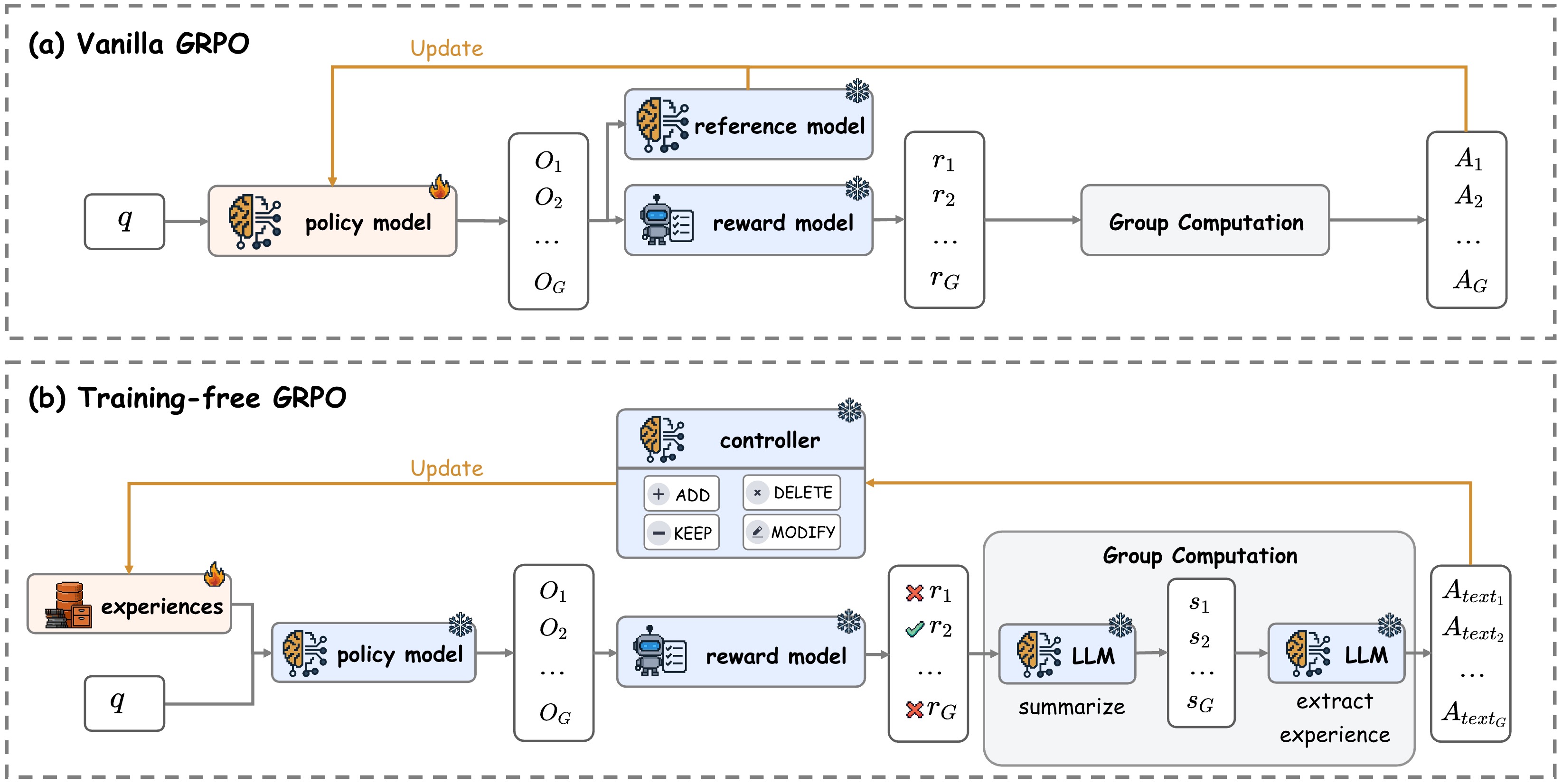
The image presents a comparative diagram illustrating two architectures of Group Reciprocal Proximal Optimization (GRPO): (a) Vanilla GRPO and (b) Training-free GRPO. Both architectures share a common goal of updating a policy model based on feedback from reference and reward models, culminating in group computation and action selection. The diagram highlights the differences in how experiences are handled and utilized within each approach.
### Components/Axes
The diagram consists of several key components:
* **Policy Model:** Represented by a brain-like icon, this model is updated in both architectures.
* **Reference Model:** Present in both architectures, providing outputs (O1, O2, … OG).
* **Reward Model:** Present in both architectures, generating rewards (r1, r2, … rG).
* **Group Computation:** A central block in both architectures, processing outputs and rewards.
* **Actions (A1, A2, … AG):** The final output of the system, representing the selected actions.
* **Experiences:** A collection of data points, only present in the Training-free GRPO architecture.
* **LLM (Large Language Model):** Used in the Training-free GRPO to summarize and extract experience.
* **Controller:** A component in the Training-free GRPO, allowing for actions like adding, deleting, keeping, or modifying elements.
* **Update Arrows:** Yellow arrows indicating the flow of updates to the policy model.
* **Data Flow Arrows:** Black arrows representing the flow of data between components.
### Detailed Analysis or Content Details
**(a) Vanilla GRPO:**
* A square box labeled "q" is positioned to the left of the policy model.
* The policy model receives an update signal (yellow arrow) from the reference and reward models.
* The reference model outputs O1, O2, and up to OG.
* The reward model outputs r1, r2, and up to rG.
* The Group Computation block processes these outputs and rewards, resulting in actions A1, A2, and up to AG.
**(b) Training-free GRPO:**
* A collection of experiences (represented by brain icons) is positioned to the left of the policy model.
* The policy model receives an update signal (yellow arrow).
* The reference model outputs Xr1, Xr2, and up to XrG.
* The reward model outputs r1, r2, and up to rG.
* An LLM is used to summarize the experiences, generating s1, s2, and up to sG.
* Another LLM is used to extract experience, generating Atext1, Atext2, and up to AtextG.
* A controller is present, with options to "ADD", "DELETE", "KEEP", and "MODIFY".
* The Group Computation block processes the outputs from the reward model and LLM, resulting in actions Atext1, Atext2, and up to AtextG.
### Key Observations
* The Training-free GRPO architecture incorporates an LLM and a controller, suggesting a more dynamic and adaptable approach compared to the Vanilla GRPO.
* The Vanilla GRPO relies directly on the outputs of the reference and reward models, while the Training-free GRPO utilizes an LLM to process experiences and generate summaries.
* The use of "Xr" in the Training-free GRPO suggests a transformation or modification of the reference model outputs.
* The actions in the Training-free GRPO are labeled "Atext", indicating they might be textual or represent a different type of output compared to the Vanilla GRPO.
### Interpretation
The diagram illustrates two distinct approaches to GRPO. The Vanilla GRPO represents a more traditional, model-based approach, where the policy model is directly updated based on the outputs of predefined reference and reward models. The Training-free GRPO, on the other hand, introduces a layer of abstraction through the use of an LLM and a controller. This allows the system to learn from experiences, adapt its behavior, and potentially generate more nuanced or context-aware actions. The inclusion of a controller suggests the ability to actively manage and refine the learning process. The "Xr" notation implies a potential pre-processing step applied to the reference model outputs before they are used in the group computation. The difference in action labeling ("A" vs. "Atext") hints at a potential shift in the nature of the actions generated by each architecture. The diagram suggests a move towards more flexible and adaptable GRPO systems that can leverage the power of LLMs to learn from experience and generate more sophisticated behaviors.