TECHNICAL ASSET FINGERPRINT
5d6ed2db8d217e673d88f667
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
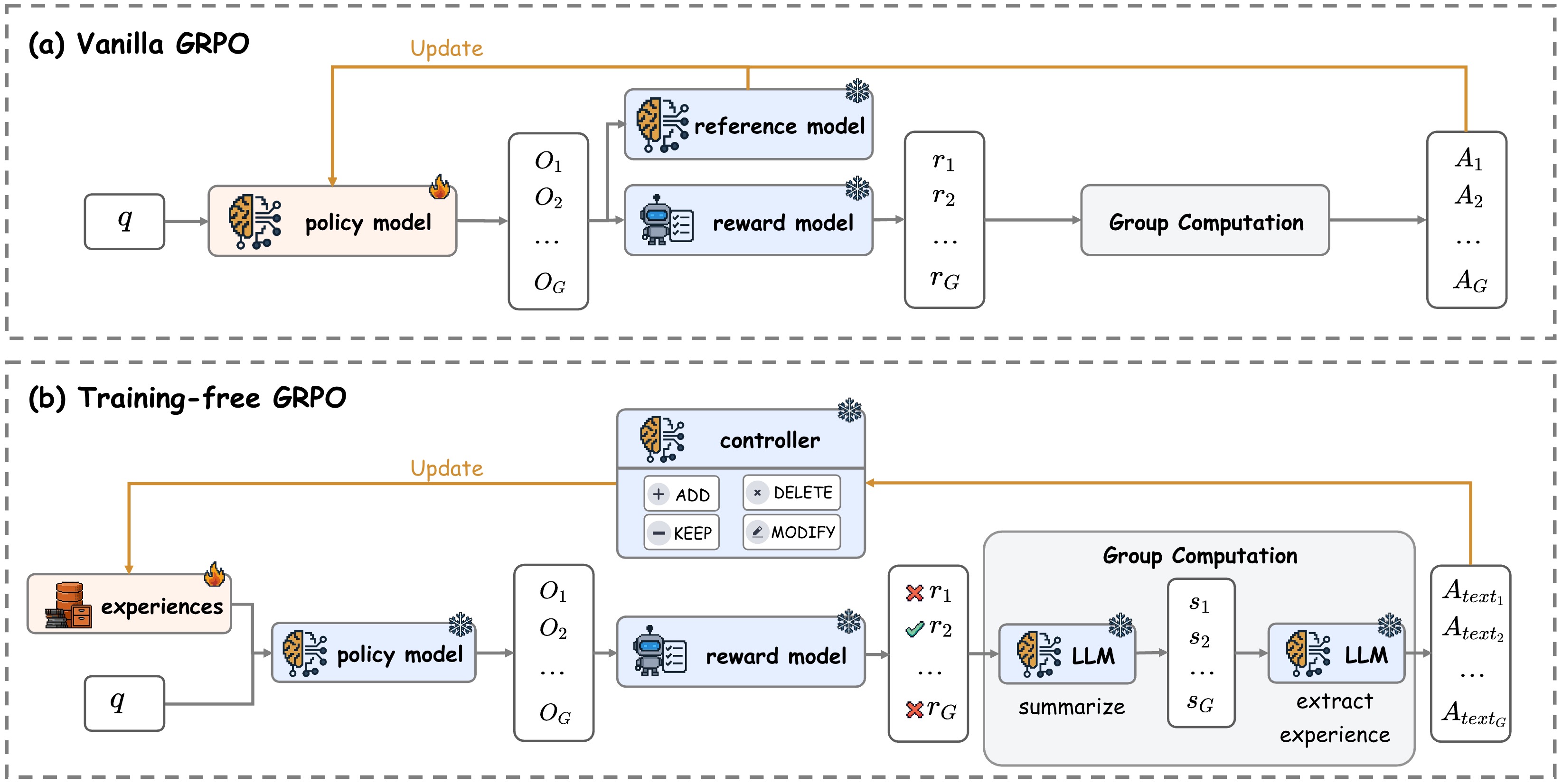
## Diagram: Comparison of Vanilla GRPO and Training-free GRPO Architectures
### Overview
The image is a technical diagram comparing two reinforcement learning architectures for Large Language Models (LLMs): "(a) Vanilla GRPO" and "(b) Training-free GRPO". It illustrates the flow of data, model components, and update mechanisms for each method. The diagram uses icons (brain, robot, database, snowflake, fire) and labeled boxes connected by arrows to depict the process.
### Components/Axes
The diagram is divided into two horizontal panels, separated by a dashed line.
**Panel (a): Vanilla GRPO**
* **Title:** "(a) Vanilla GRPO" (top-left corner).
* **Input:** A box labeled `q` (query).
* **Core Models:**
* `policy model`: A box with a brain icon and a fire emoji (indicating it is updated/trained).
* `reference model`: A box with a brain icon and a snowflake emoji (indicating it is frozen).
* `reward model`: A box with a robot icon and a snowflake emoji.
* **Data Flow:**
* Outputs from the policy model are labeled `O₁`, `O₂`, ..., `O_G` (a group of outputs).
* Outputs from the reward model are labeled `r₁`, `r₂`, ..., `r_G` (a group of rewards).
* A box labeled `Group Computation` processes the rewards.
* Final outputs are labeled `A₁`, `A₂`, ..., `A_G` (likely advantages or actions).
* **Update Loop:** An orange arrow labeled `Update` flows from the `Group Computation` output back to the `policy model`.
**Panel (b): Training-free GRPO**
* **Title:** "(b) Training-free GRPO" (top-left corner of the lower panel).
* **Input:** A box labeled `q` (query) and a box labeled `experiences` with a database icon and a fire emoji.
* **Core Models:**
* `policy model`: A box with a brain icon and a snowflake emoji (frozen).
* `reward model`: A box with a robot icon and a snowflake emoji.
* `controller`: A box with a brain icon and a snowflake emoji, containing four buttons: `+ ADD`, `× DELETE`, `- KEEP`, `✎ MODIFY`.
* `LLM` (two instances): Boxes with brain icons and snowflake emojis, labeled `summarize` and `extract experience` respectively.
* **Data Flow:**
* Outputs from the policy model are labeled `O₁`, `O₂`, ..., `O_G`.
* Outputs from the reward model are labeled with symbols and `r` values: `✗ r₁`, `✓ r₂`, ..., `✗ r_G` (indicating rejected and accepted rewards).
* A large box labeled `Group Computation` contains the two `LLM` instances.
* Intermediate summaries are labeled `s₁`, `s₂`, ..., `s_G`.
* Final outputs are labeled `A_text₁`, `A_text₂`, ..., `A_text_G` (text-based advantages or actions).
* **Update Loop:** An orange arrow labeled `Update` flows from the `Group Computation` output back to the `experiences` box. Another orange arrow connects the `controller` to the `experiences` box.
### Detailed Analysis
**Vanilla GRPO Flow:**
1. A query `q` is fed into a trainable `policy model`.
2. The policy model generates a group of outputs `O₁` to `O_G`.
3. These outputs are evaluated by two frozen models: a `reference model` and a `reward model`.
4. The reward model produces scalar rewards `r₁` to `r_G`.
5. These rewards undergo `Group Computation` to produce advantages `A₁` to `A_G`.
6. The computed advantages are used to `Update` the policy model, completing the training loop.
**Training-free GRPO Flow:**
1. A query `q` and a set of `experiences` (from a database) are fed into a **frozen** `policy model`.
2. The policy model generates outputs `O₁` to `O_G`.
3. These outputs are evaluated by a frozen `reward model`, which produces rewards marked as accepted (`✓`) or rejected (`✗`).
4. The rewards enter a `Group Computation` module.
5. Inside this module, a frozen `LLM` first `summarize`s the group, producing summaries `s₁` to `s_G`.
6. A second frozen `LLM` then performs `extract experience` on these summaries to produce final text-based outputs `A_text₁` to `A_text_G`.
7. These text outputs are used to `Update` the `experiences` database.
8. A separate frozen `controller` (with ADD, DELETE, KEEP, MODIFY functions) also interacts with the `experiences` database.
### Key Observations
1. **Model State:** In Vanilla GRPO, only the policy model is trained (fire emoji). In Training-free GRPO, all models (policy, reward, controller, LLMs) are frozen (snowflake emoji); learning happens by updating the external `experiences` database.
2. **Output Nature:** Vanilla GRPO produces numerical advantages (`A_G`). Training-free GRPO produces textual advantages or actions (`A_text_G`).
3. **Reward Processing:** Vanilla GRPO uses raw rewards directly. Training-free GRPO filters rewards (✓/✗) and processes them through summarization and extraction steps using LLMs.
4. **Update Target:** The update in (a) targets the model's parameters. The update in (b) targets an external memory (`experiences`).
5. **Controller:** The `controller` is a unique component in (b), suggesting a mechanism for curating the experience database through discrete operations (add, delete, keep, modify).
### Interpretation
This diagram contrasts two paradigms for improving LLM-based agents via reinforcement learning.
* **Vanilla GRPO** represents a traditional **parametric learning** approach. The agent (policy model) improves by directly adjusting its internal weights based on computed advantages from a reward model. This is analogous to standard policy gradient methods.
* **Training-free GRPO** represents a **non-parametric or retrieval-augmented learning** approach. The agent's core model is frozen. Instead of changing weights, it improves by maintaining and updating an external database of "experiences." The system uses frozen LLMs to reason about groups of outcomes, summarize them, and extract textual lessons, which are then stored. The `controller` acts as a manager for this experience bank.
The key implication is that Training-free GRPO aims to achieve adaptation and learning without the computational cost and potential instability of backpropagation-based training. It shifts the learning burden from model parameters to a structured memory system, potentially offering more interpretable and controllable updates (via the controller's discrete actions). The use of LLMs for summarization and extraction suggests the system leverages the model's existing reasoning capabilities to create high-level, textual knowledge from raw experiences.
DECODING INTELLIGENCE...