# Technical Document Extraction: GRPO System Architectures
## Diagram Overview
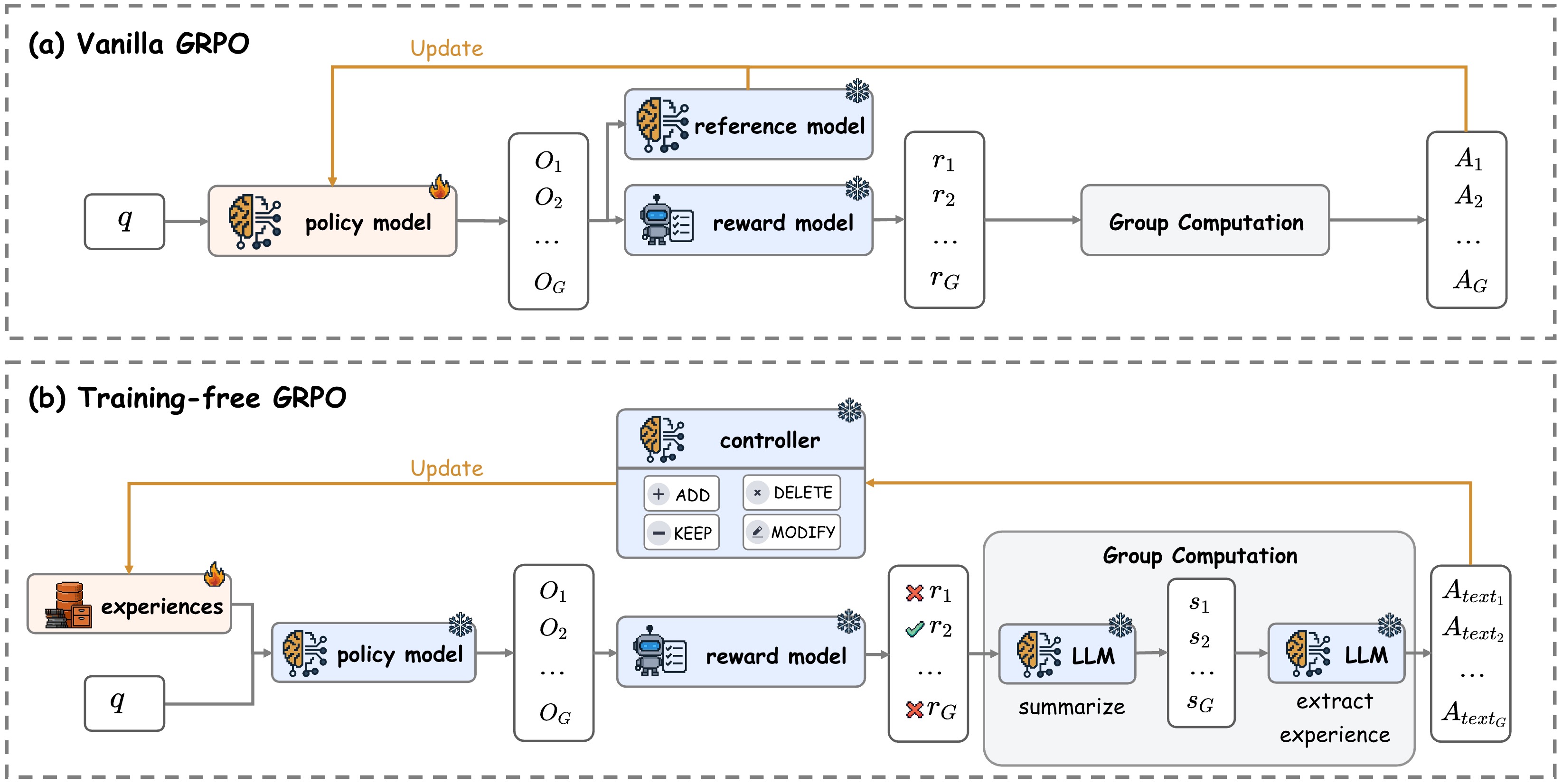
The image contains two comparative diagrams of Group Relative Policy Optimization (GRPO) system architectures:
1. **Vanilla GRPO** (Top diagram)
2. **Training-free GRPO** (Bottom diagram)
---
## (a) Vanilla GRPO Architecture
### Component Breakdown
1. **Policy Model**
- Input: `q` (query/input)
- Output: `O₁, O₂, ..., O_G` (group outputs)
- Visual: Brain icon with neural network lines
2. **Reference Model**
- Input: `O₁, O₂, ..., O_G`
- Output: `r₁, r₂, ..., r_G` (reference rewards)
- Visual: Brain icon with snowflake
3. **Reward Model**
- Input: `O₁, O₂, ..., O_G`
- Output: `r₁, r₂, ..., r_G` (reward signals)
- Visual: Robot icon with checklist
4. **Group Computation**
- Input: `r₁, r₂, ..., r_G`
- Output: `A₁, A₂, ..., A_G` (action outputs)
- Visual: Gray rectangle
### Flow Diagram
```
q → [Policy Model] → [Reference Model] → [Reward Model] → [Group Computation] → A₁...A_G
```
### Key Annotations
- Orange "Update" arrow connecting Policy Model to Reference/Reward Models
- Fire icon on Policy Model (possibly indicating optimization process)
- No explicit numerical data present
---
## (b) Training-free GRPO Architecture
### Component Breakdown
1. **Experiences**
- Input: External data source
- Output: Feeds into Policy Model
- Visual: Filing cabinet icon
2. **Controller**
- Input: Policy Model outputs
- Actions: ADD, DELETE, KEEP, MODIFY
- Visual: Robot icon with control buttons
3. **Reward Model**
- Input: `O₁, O₂, ..., O_G`
- Output: `r₁, r₂, ..., r_G` (with X/✓ annotations)
- Visual: Robot icon with checklist
4. **LLM (Large Language Model)**
- Input: `s₁, s₂, ..., s_G` (summarized experiences)
- Output: `A_text₁, A_text₂, ..., A_text_G` (text actions)
- Functions: Summarize, Extract Experience
- Visual: Brain icon with neural network
### Flow Diagram
```
q → [Policy Model] → [Controller] → [Reward Model] → [LLM] → A_text₁...A_text_G
```
### Key Annotations
- Orange "Update" arrow connecting Experiences to Policy Model
- Fire icon on Experiences component
- X marks on `r₁` and `r_G` (rejected rewards)
- ✓ mark on `r₂` (accepted reward)
- LLM processes summarized experiences (`s₁...s_G`) before generating text actions
---
## Comparative Analysis
| Feature | Vanilla GRPO | Training-free GRPO |
|------------------------|-----------------------------|-----------------------------|
| **Learning Mechanism** | Supervised reference model | Experience-based controller |
| **Output Type** | Action vectors (A₁...A_G) | Text actions (A_text₁...A_text_G) |
| **Experience Handling**| No | Explicit experience module |
| **Reward Processing** | Direct computation | Filtered with X/✓ annotations |
| **LLM Integration** | No | Central component |
---
## Spatial Grounding & Trend Verification
- **Legend Confirmation**: No explicit legend present; component icons serve as visual identifiers
- **Flow Direction**: All diagrams follow left-to-right processing flow
- **Data Flow Validation**:
- Vanilla: Numerical rewards → Group computation → Action vectors
- Training-free: Textual experiences → Controller → Filtered rewards → LLM → Text actions
---
## Missing Elements
- No numerical data points or statistical values present
- No explicit time axis or performance metrics
- No comparative scale between diagrams
---
## Conclusion
The diagrams illustrate two GRPO variants with distinct processing pipelines. The training-free version introduces experience management and LLM integration, while the vanilla version follows a more traditional reference/reward model architecture. Both systems maintain group-based processing (`O_G`, `r_G`, `A_G`) but differ fundamentally in their learning mechanisms and output modalities.