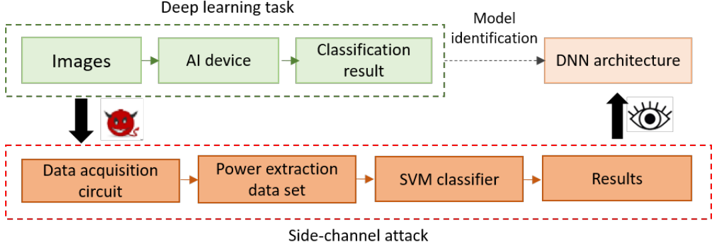
## Diagram: Deep Learning Task vs. Side-Channel Attack
### Overview
The image presents a diagram comparing a deep learning task with a side-channel attack. It illustrates the flow of data and processes in both scenarios, highlighting how a side-channel attack can be used to infer information about the deep learning model.
### Components/Axes
* **Title:** Deep learning task vs. Side-channel attack
* **Top Section (Deep learning task):**
* Enclosed in a green dashed box labeled "Deep learning task".
* Components:
* "Images" (green box)
* "AI device" (green box)
* "Classification result" (green box)
* **Bottom Section (Side-channel attack):**
* Enclosed in a red dashed box labeled "Side-channel attack".
* Components:
* "Data acquisition circuit" (orange box)
* "Power extraction data set" (orange box)
* "SVM classifier" (orange box)
* "Results" (orange box)
* **Connecting Elements:**
* Arrow from "Images" to "Data acquisition circuit" with a devil face icon.
* Dotted arrow from "Classification result" to "DNN architecture" labeled "Model identification".
* Arrow from "Results" to "DNN architecture" with an eye icon.
### Detailed Analysis
* **Deep Learning Task Flow:** The deep learning task starts with "Images" as input, which are processed by an "AI device" to produce a "Classification result".
* **Side-Channel Attack Flow:** The side-channel attack begins with a "Data acquisition circuit", which captures data related to the deep learning task. This data is used to create a "Power extraction data set". An "SVM classifier" processes this data to produce "Results".
* **Attack Vector:** The arrow from "Images" to "Data acquisition circuit" with the devil face icon indicates that the side-channel attack is initiated during the image processing stage of the deep learning task.
* **Model Identification:** The dotted arrow from "Classification result" to "DNN architecture" represents the normal model identification process.
* **Inference:** The arrow from "Results" to "DNN architecture" with the eye icon suggests that the side-channel attack results can be used to infer information about the "DNN architecture".
### Key Observations
* The diagram clearly distinguishes between the normal operation of a deep learning task and a side-channel attack targeting it.
* The side-channel attack leverages power consumption data to infer information about the deep learning model.
* The devil face icon emphasizes the malicious nature of the side-channel attack.
### Interpretation
The diagram illustrates how a side-channel attack can compromise the security of a deep learning system. By monitoring the power consumption of the "AI device" during image processing, an attacker can extract sensitive information about the "DNN architecture". This information can then be used to reverse engineer the model, potentially leading to intellectual property theft or the development of adversarial attacks. The diagram highlights the importance of implementing countermeasures to protect deep learning systems against side-channel attacks.