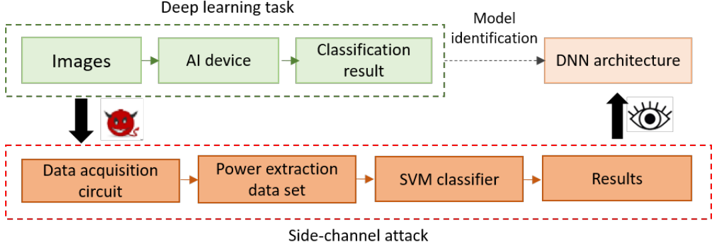
## Diagram: Deep Learning Task vs. Side-Channel Attack Workflow
### Overview
The diagram contrasts two parallel processes:
1. **Legitimate Deep Learning Task** (top section, green boxes)
2. **Side-Channel Attack** (bottom section, orange boxes)
Both processes interact with a shared "DNN Architecture" component, with the attack aiming to reverse-engineer the model.
---
### Components/Axes
#### Top Section (Deep Learning Task):
- **Images** → **AI Device** → **Classification Result**
- Arrows indicate sequential flow.
- Dashed line labeled **"Model identification"** connects to **DNN Architecture**.
- Eye icon with upward arrow suggests model transparency or monitoring.
#### Bottom Section (Side-Channel Attack):
- **Data Acquisition Circuit** → **Power Extraction Dataset** → **SVM Classifier** → **Results**
- Red dashed line labeled **"Side-channel attack"** connects the two sections.
- Devil emoji (😈) symbolizes malicious intent.
#### Shared Elements:
- **DNN Architecture**: Central target for both processes.
- **Legend**:
- Green boxes = Legitimate workflow.
- Orange boxes = Attack workflow.
---
### Detailed Analysis
1. **Legitimate Workflow**:
- Images are processed by an AI device to produce classification results.
- The model architecture is inferred from the classification outcome (dashed line).
2. **Attack Workflow**:
- A data acquisition circuit extracts power consumption data during AI operations.
- The power data is analyzed using an SVM classifier to reconstruct the DNN architecture.
- The devil emoji emphasizes the adversarial nature of this process.
3. **Interaction**:
- The attack aims to reverse-engineer the DNN architecture (via power data) to replicate or exploit the model.
- The eye icon implies potential detection mechanisms for such attacks.
---
### Key Observations
- **Color Coding**: Green (legitimate) vs. Orange (attack) visually distinguishes the two processes.
- **Dashed Lines**: Indicate indirect relationships (e.g., model identification via classification results).
- **Icons**:
- Devil (😈) = Malicious intent.
- Eye = Surveillance or detection.
---
### Interpretation
This diagram illustrates a **security vulnerability** in AI systems:
- **Legitimate Use**: Focuses on input (images) → processing (AI device) → output (classification).
- **Attack Vector**: Exploits physical side channels (power consumption) to extract model architecture details.
- **Implications**:
- Attackers can reconstruct DNN architectures without access to training data or code.
- The SVM classifier in the attack workflow suggests machine learning is used to map power traces to model structures.
- The eye icon hints at countermeasures (e.g., anomaly detection in power usage).
The diagram underscores the need for **hardware-aware security** in AI deployments to prevent model theft via side-channel attacks.