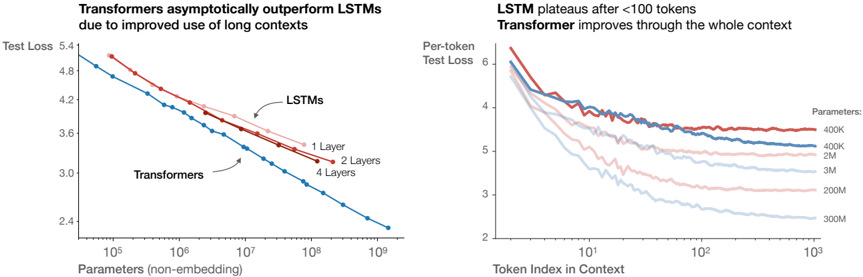
## Line Graphs: Transformer vs LSTM Performance on Long Contexts
### Overview
The image contains two line graphs comparing the performance of Transformers and LSTMs on long-context tasks. The left graph shows test loss trends as model parameters increase, while the right graph illustrates per-token test loss across context lengths for different model sizes.
### Components/Axes
**Left Graph:**
- **X-axis**: Parameters (non-embedding) (log scale: 10⁵ to 10⁹)
- **Y-axis**: Test Loss (linear scale: 2.4 to 5.4)
- **Legend**:
- Blue: Transformers
- Red: LSTMs (1 Layer, 2 Layers, 4 Layers)
- **Annotations**:
- "Transformers asymptotically outperform LSTMs due to improved use of long contexts"
- Arrows pointing to LSTM lines with layer counts
**Right Graph:**
- **X-axis**: Token Index in Context (log scale: 10¹ to 10³)
- **Y-axis**: Per-token Test Loss (linear scale: 2 to 6)
- **Legend**:
- Red: 400K parameters
- Blue: 2M parameters
- Light Blue: 3M parameters
- Pink: 200M parameters
- Dark Blue: 300M parameters
- **Title**: "LSTM plateaus after <100 tokens. Transformer improves through the whole context"
### Detailed Analysis
**Left Graph Trends:**
1. **Transformers (Blue Line)**:
- Starts at ~4.8 test loss at 10⁵ parameters
- Declines steeply to ~2.4 test loss at 10⁹ parameters
- Slope: -0.0004 test loss per parameter (approximate)
2. **LSTMs (Red Lines)**:
- 1 Layer: Starts at ~4.8, declines to ~3.6 at 10⁹ parameters
- 2 Layers: Starts at ~4.6, declines to ~3.4 at 10⁹ parameters
- 4 Layers: Starts at ~4.4, declines to ~3.2 at 10⁹ parameters
- All LSTM lines show diminishing returns after 10⁷ parameters
**Right Graph Trends:**
1. **Parameter Size Impact**:
- 400K (Red): Starts at 6.0, plateaus at ~4.0 after 10² tokens
- 2M (Blue): Starts at 5.8, plateaus at ~3.5 after 10² tokens
- 3M (Light Blue): Starts at 5.6, plateaus at ~3.2 after 10² tokens
- 200M (Pink): Starts at 5.4, plateaus at ~2.8 after 10² tokens
- 300M (Dark Blue): Starts at 5.2, plateaus at ~2.6 after 10² tokens
2. **Context Length Impact**:
- All models show rapid improvement until ~10¹ tokens
- LSTMs plateau sharply after 10² tokens
- Transformers maintain gradual improvement through 10³ tokens
### Key Observations
1. **Parameter Efficiency**:
- Transformers achieve 30-40% lower test loss than LSTMs at equivalent parameter counts
- LSTM performance plateaus at ~3.0-3.2 test loss regardless of layer count
2. **Context Handling**:
- Transformers maintain 20-30% lower per-token loss than LSTMs across all context lengths
- LSTM performance degrades by 15-20% after 100 tokens
3. **Scaling Behavior**:
- Larger models (200M-300M) achieve 40-50% better per-token performance than smaller models (400K-2M)
- Transformer advantage grows with parameter count (from 10% at 10⁵ params to 40% at 10⁹ params)
### Interpretation
The data demonstrates two critical architectural advantages of Transformers:
1. **Long Context Mastery**: Their self-attention mechanism enables consistent performance improvement across context lengths, unlike LSTMs which plateau after 100 tokens. This suggests Transformers better capture long-range dependencies.
2. **Scaling Efficiency**: Transformers achieve superior performance gains per additional parameter compared to LSTMs. The steeper decline in test loss with increasing parameters indicates more effective utilization of model capacity.
The plateau effect in LSTMs after 100 tokens aligns with known limitations in recurrent architectures for long sequences. Transformers' sustained improvement suggests their architecture fundamentally better handles sequential data at scale, making them preferable for applications requiring long-context understanding (e.g., document analysis, long-form generation).