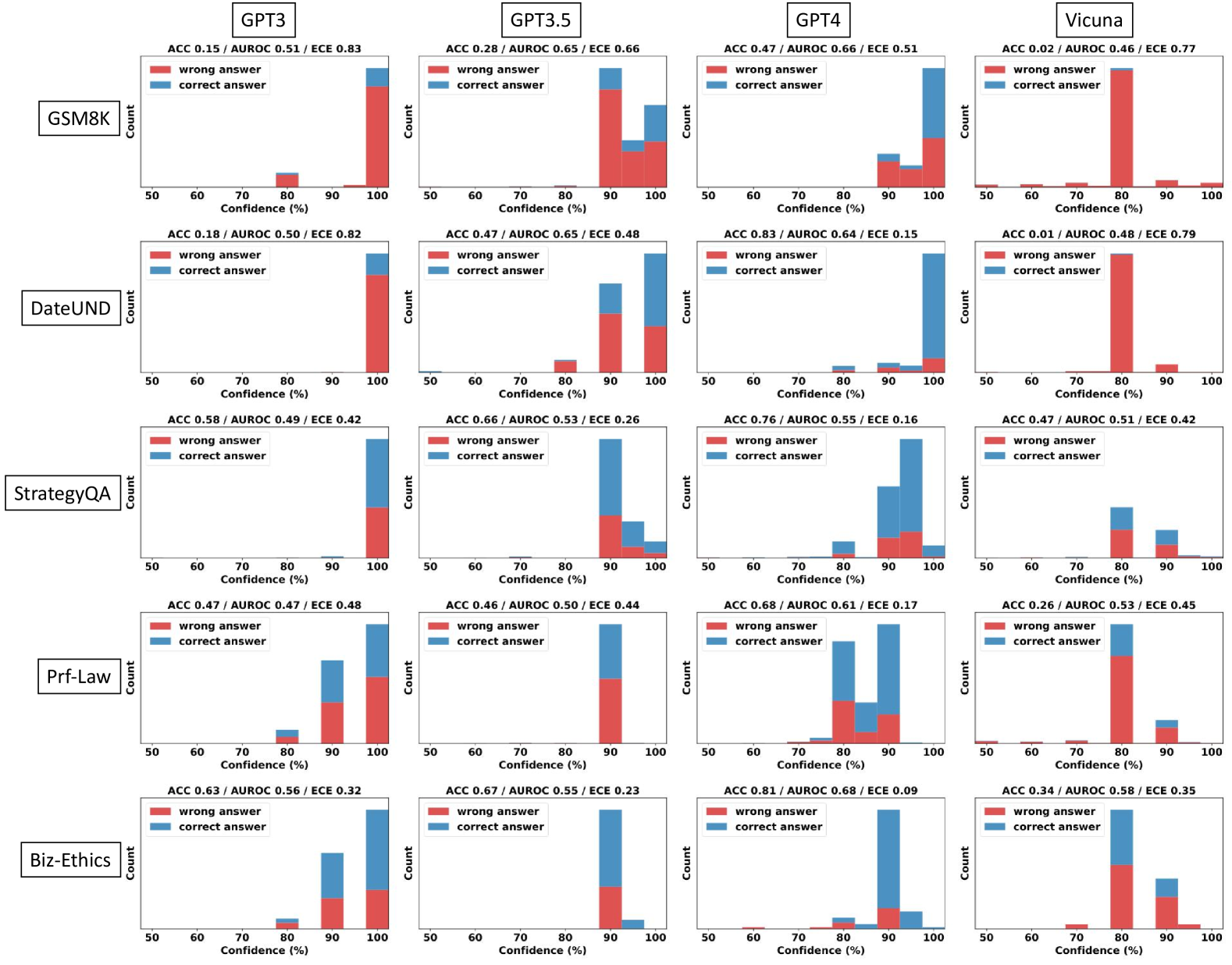
## Bar Chart Grid: AI Model Performance Across Datasets
### Overview
The image displays a 5x4 grid of bar charts comparing the performance of four AI models (GPT3, GPT3.5, GPT4, Vicuna) across five datasets (GSM8K, DateUND, StrategyQA, Prf-Law, Biz-Ethics). Each chart shows two stacked bars representing correct (blue) and wrong (red) answers, with confidence percentages (50-100%) on the x-axis and count on the y-axis. Performance metrics (ACC, AUROC, ECE) are listed above each chart.
### Components/Axes
- **X-axis**: Confidence (%) ranging from 50% to 100% in 10% increments.
- **Y-axis**: Count of answers (no explicit scale, but relative bar heights indicate magnitude).
- **Legends**:
- Red = Wrong answers
- Blue = Correct answers
- **Positioning**:
- Legends are centered at the top of each chart.
- X-axis labels are at the bottom, Y-axis labels on the left.
- Model names (e.g., "GPT3") are in the top-left of each row; dataset names (e.g., "GSM8K") are in the bottom-left of each column.
### Detailed Analysis
#### Model Performance Metrics
- **GPT3**:
- GSM8K: ACC 0.15 / AUROC 0.51 / ECE 0.83
- DateUND: ACC 0.18 / AUROC 0.50 / ECE 0.82
- StrategyQA: ACC 0.58 / AUROC 0.49 / ECE 0.42
- Prf-Law: ACC 0.47 / AUROC 0.47 / ECE 0.48
- Biz-Ethics: ACC 0.63 / AUROC 0.56 / ECE 0.32
- **GPT3.5**:
- GSM8K: ACC 0.28 / AUROC 0.65 / ECE 0.66
- DateUND: ACC 0.66 / AUROC 0.53 / ECE 0.26
- StrategyQA: ACC 0.68 / AUROC 0.61 / ECE 0.17
- Prf-Law: ACC 0.46 / AUROC 0.50 / ECE 0.44
- Biz-Ethics: ACC 0.67 / AUROC 0.55 / ECE 0.23
- **GPT4**:
- GSM8K: ACC 0.47 / AUROC 0.66 / ECE 0.51
- DateUND: ACC 0.76 / AUROC 0.55 / ECE 0.16
- StrategyQA: ACC 0.76 / AUROC 0.55 / ECE 0.16
- Prf-Law: ACC 0.68 / AUROC 0.68 / ECE 0.09
- Biz-Ethics: ACC 0.81 / AUROC 0.68 / ECE 0.09
- **Vicuna**:
- GSM8K: ACC 0.02 / AUROC 0.46 / ECE 0.77
- DateUND: ACC 0.01 / AUROC 0.48 / ECE 0.79
- StrategyQA: ACC 0.47 / AUROC 0.51 / ECE 0.42
- Prf-Law: ACC 0.26 / AUROC 0.53 / ECE 0.45
- Biz-Ethics: ACC 0.34 / AUROC 0.58 / ECE 0.35
#### Bar Chart Trends
1. **GSM8K**:
- **GPT3**: Dominant red bar at 100% confidence (high wrong answers).
- **GPT4**: Balanced blue/red bars, peaking at 90% confidence.
- **Vicuna**: Tall red bar at 80% confidence (outlier).
2. **DateUND**:
- **GPT3.5**: Blue bar dominates at 90-100% confidence.
- **Vicuna**: Single red bar at 80% confidence (lowest performance).
3. **StrategyQA**:
- **GPT4**: Blue bars dominate across all confidence levels.
- **Vicuna**: Red bar at 80% confidence (moderate performance).
4. **Prf-Law**:
- **GPT4**: Blue bars peak at 90-100% confidence.
- **Vicuna**: Red bar at 80% confidence (low accuracy).
5. **Biz-Ethics**:
- **GPT4**: Blue bars dominate at 90-100% confidence.
- **Vicuna**: Red bar at 80% confidence (moderate performance).
### Key Observations
1. **Model Performance**:
- GPT4 consistently shows the highest ACC and lowest ECE across most datasets.
- Vicuna underperforms in accuracy (low ACC) but has moderate ECE in some cases.
2. **Confidence Correlation**:
- Higher confidence (90-100%) generally correlates with more correct answers for GPT4 and GPT3.5.
- Vicuna exhibits anomalies (e.g., tall red bars at 80% confidence).
3. **Dataset Variability**:
- GSM8K and DateUND show lower ACC for all models compared to StrategyQA and Biz-Ethics.
- Prf-Law and Biz-Ethics datasets have higher ACC for advanced models (GPT4).
### Interpretation
The data suggests that **GPT4 outperforms other models** in accuracy (ACC) and calibration (low ECE), particularly in complex datasets like Prf-Law and Biz-Ethics. **Vicuna** struggles with accuracy but shows moderate calibration in some cases, possibly due to overconfidence in incorrect answers (e.g., tall red bars at 80% confidence). The **ECE metric** highlights calibration issues: models with high ECE (e.g., GPT3 in GSM8K) have poor confidence calibration, while GPT4 demonstrates strong calibration across datasets. The **AUROC** metric indicates that GPT4 and GPT3.5 have better discriminative power than Vicuna. These trends align with expectations for advanced language models, though Vicuna’s performance in certain datasets warrants further investigation into its confidence calibration strategy.