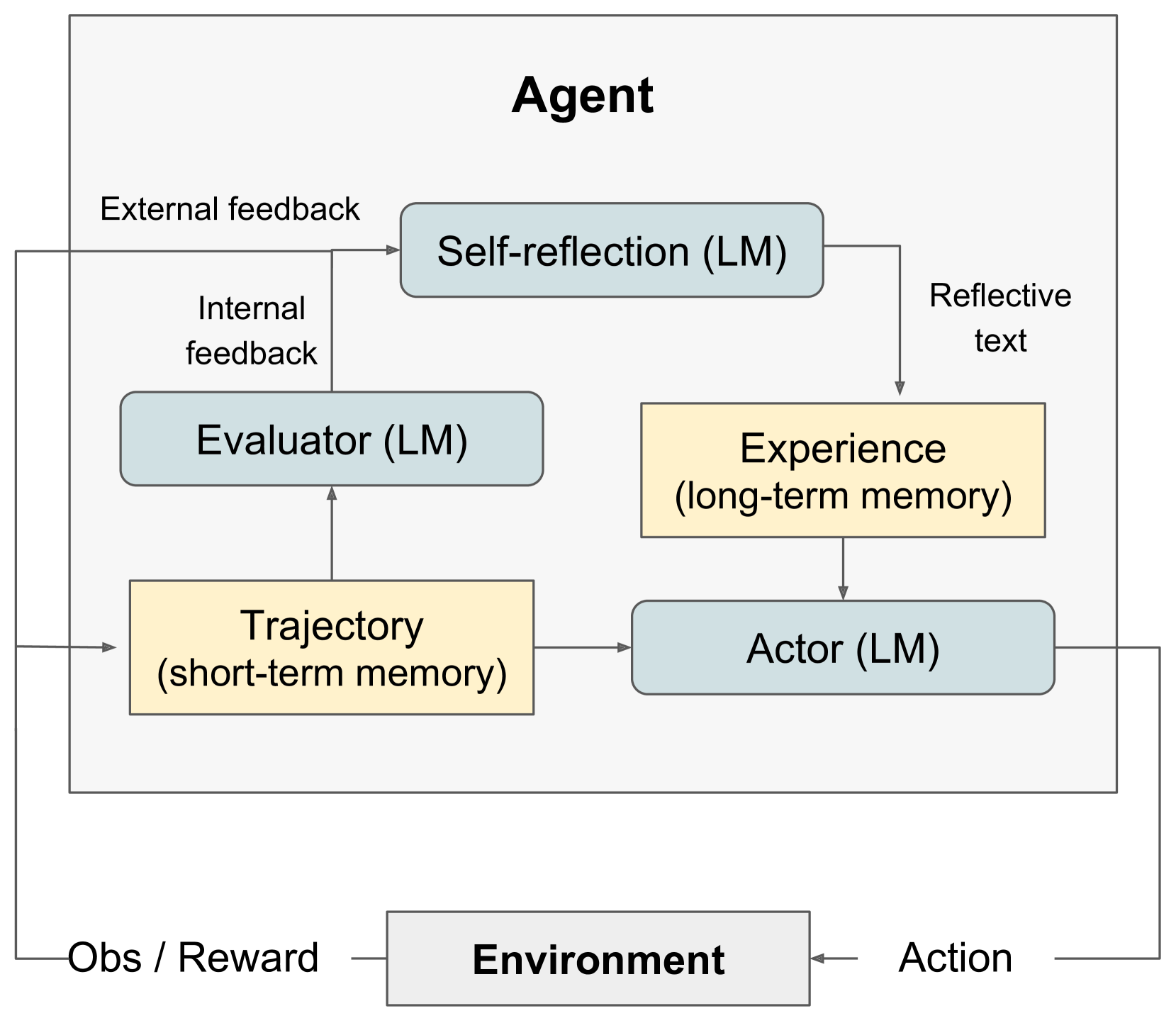
# Technical Diagram Analysis: Agent Architecture
This document describes a technical flow diagram illustrating the internal architecture of an AI **Agent** and its interaction with an **Environment**.
## 1. High-Level Components
The diagram is divided into two primary regions:
* **Agent (Main Container):** A large bounding box containing the internal logic, memory, and processing units.
* **Environment:** A separate entity at the bottom that interacts with the Agent via a feedback loop.
## 2. Internal Agent Components
The Agent's internal architecture consists of five functional blocks, categorized by color:
### Processing Units (Light Blue Rounded Rectangles)
* **Self-reflection (LM):** Located at the top-center. It processes feedback to generate reflective insights.
* **Evaluator (LM):** Located in the middle-left. It analyzes the agent's trajectory.
* **Actor (LM):** Located in the bottom-right. It is the final decision-making unit that interacts with the environment.
### Memory Units (Light Yellow Rectangles)
* **Trajectory (short-term memory):** Located in the bottom-left. It stores immediate sequences of events.
* **Experience (long-term memory):** Located in the middle-right. It stores accumulated knowledge and reflections.
## 3. Information Flow and Connections
### External Interaction Loop
1. **Action:** An arrow originates from the **Actor (LM)**, exits the Agent container, and points to the **Environment**.
2. **Obs / Reward:** An arrow originates from the **Environment** and splits into two paths:
* One path enters the **Trajectory (short-term memory)**.
* The other path leads upward toward the **Self-reflection (LM)** unit, labeled as **"External feedback"**.
### Internal Processing Loop
1. **Trajectory to Evaluator:** An arrow moves from **Trajectory (short-term memory)** up to the **Evaluator (LM)**.
2. **Evaluator to Self-reflection:** An arrow moves from the **Evaluator (LM)** up to the **Self-reflection (LM)**, labeled as **"Internal feedback"**.
3. **Self-reflection to Experience:** An arrow moves from **Self-reflection (LM)** down to **Experience (long-term memory)**, labeled as **"Reflective text"**.
4. **Memory Integration:**
* An arrow moves from **Trajectory (short-term memory)** horizontally to the **Actor (LM)**.
* An arrow moves from **Experience (long-term memory)** vertically down to the **Actor (LM)**.
## 4. Summary of Text Labels
| Category | Label Text |
| :--- | :--- |
| **Main Entities** | Agent, Environment |
| **LM Components** | Self-reflection (LM), Evaluator (LM), Actor (LM) |
| **Memory Types** | Trajectory (short-term memory), Experience (long-term memory) |
| **Data/Signals** | External feedback, Internal feedback, Reflective text, Obs / Reward, Action |
## 5. Functional Logic
The diagram depicts a reinforcement learning or autonomous agent loop where the **Actor** performs an **Action** in the **Environment**. The resulting **Observation/Reward** is stored in **Short-term memory** and sent as **External feedback**. The **Evaluator** provides **Internal feedback** based on the current **Trajectory**. Both feedback types are processed by the **Self-reflection** module to create **Reflective text**, which is stored in **Long-term memory**. The **Actor** then makes future decisions based on both short-term trajectory and long-term experience.