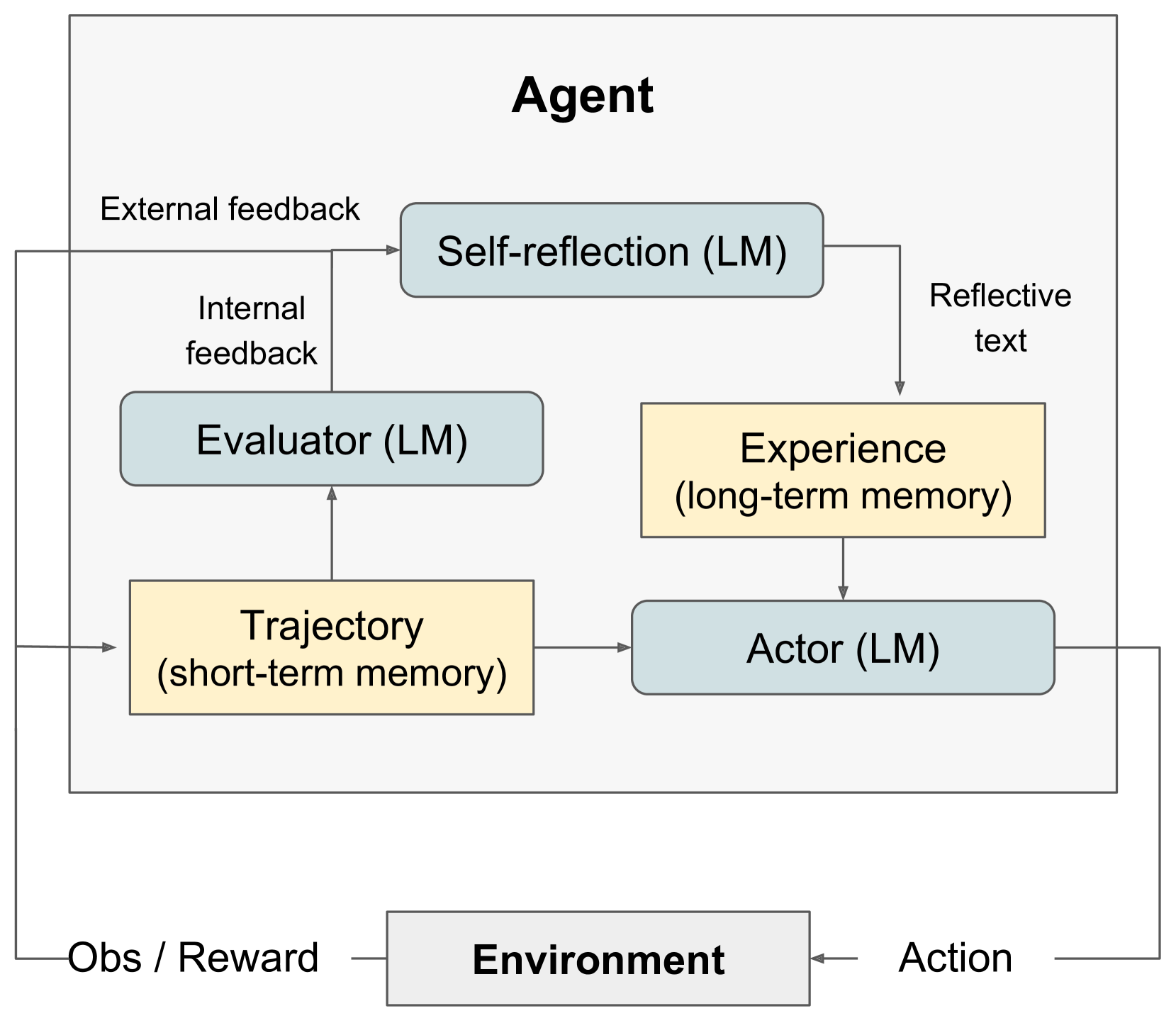
## [Diagram Type]: Agent Architecture Flowchart
### Overview
This image is a technical diagram illustrating the architecture of an AI agent system. It depicts the agent's internal components, their interconnections, and the agent's interaction with an external environment. The diagram uses labeled boxes, directional arrows, and color-coding to represent different functional modules and the flow of information between them.
### Components/Axes
The diagram is structured with a large outer box labeled **"Agent"** at the top center, which contains most of the system's components. Below this box, outside its boundary, is the **"Environment"**.
**Components within the "Agent" box:**
1. **Self-reflection (LM)**: A light blue, rounded rectangle located in the top-center.
2. **Evaluator (LM)**: A light blue, rounded rectangle located in the middle-left.
3. **Actor (LM)**: A light blue, rounded rectangle located in the middle-right.
4. **Experience (long-term memory)**: A yellow rectangle located to the right of the Evaluator and above the Actor.
5. **Trajectory (short-term memory)**: A yellow rectangle located in the bottom-left.
**Component outside the "Agent" box:**
6. **Environment**: A gray rectangle located at the bottom-center.
**Information Flow Labels (on arrows):**
* **External feedback**: Points from outside the Agent box to "Self-reflection (LM)".
* **Internal feedback**: Points from "Evaluator (LM)" to "Self-reflection (LM)".
* **Reflective text**: Points from "Self-reflection (LM)" to "Experience (long-term memory)".
* **Obs / Reward**: Points from "Environment" to the "Trajectory (short-term memory)" and also to the "Evaluator (LM)".
* **Action**: Points from "Actor (LM)" to "Environment".
### Detailed Analysis
The diagram defines a closed-loop system with the following information pathways:
1. **Input to Agent**: The agent receives **"Obs / Reward"** (Observation/Reward) from the **Environment**. This input is directed to two components:
* The **"Trajectory (short-term memory)"** module.
* The **"Evaluator (LM)"** module.
2. **Internal Processing Loop**:
* The **"Trajectory (short-term memory)"** provides input to both the **"Evaluator (LM)"** and the **"Actor (LM)"**.
* The **"Evaluator (LM)"** generates **"Internal feedback"** which is sent to the **"Self-reflection (LM)"** module.
* The **"Self-reflection (LM)"** module also receives **"External feedback"** from outside the agent system.
* The **"Self-reflection (LM)"** module outputs **"Reflective text"** which is stored in the **"Experience (long-term memory)"**.
3. **Action Generation**:
* The **"Actor (LM)"** module receives input from two sources: the **"Trajectory (short-term memory)"** and the **"Experience (long-term memory)"**.
* Based on these inputs, the **"Actor (LM)"** generates an **"Action"**.
4. **Output to Environment**: The **"Action"** from the **"Actor (LM)"** is sent to the **"Environment"**, completing the interaction loop.
**Color Coding:**
* **Light Blue (Rounded Rectangles)**: Denotes active processing modules powered by a Language Model (LM): Self-reflection, Evaluator, and Actor.
* **Yellow (Rectangles)**: Denotes memory stores: short-term (Trajectory) and long-term (Experience).
* **Gray (Rectangle)**: Denotes the external Environment.
### Key Observations
* The architecture explicitly separates **short-term memory (Trajectory)** from **long-term memory (Experience)**.
* There are two distinct feedback pathways influencing the agent's learning and reflection: **Internal feedback** (from the Evaluator) and **External feedback** (from outside the agent).
* The **Actor** is the sole component that directly interfaces with the Environment to produce actions, but its decisions are informed by both immediate trajectory and accumulated long-term experience.
* The **Evaluator** serves a dual role: it processes the current trajectory and environment rewards, and it provides internal feedback to the self-reflection module.
### Interpretation
This diagram represents a sophisticated cognitive architecture for an AI agent, likely designed for complex, sequential decision-making tasks. It moves beyond a simple reactive model by incorporating **self-reflection** and **memory**.
* **Learning Mechanism**: The system suggests a form of **reinforcement learning** where the agent receives rewards from the environment. However, it enhances this with a **reflective learning** loop. The agent doesn't just act; it evaluates its own trajectory, reflects on it (incorporating both internal and external feedback), and stores these reflections as long-term experiential knowledge to guide future actions.
* **Role of Language Models (LMs)**: The "(LM)" tag on the core processing modules (Self-reflection, Evaluator, Actor) indicates that these functions are implemented using Large Language Models. This implies the agent uses natural language understanding and generation for reflection, evaluation, and decision-making.
* **Human-like Cognition**: The architecture mirrors aspects of human cognition: a short-term working memory (Trajectory), a long-term memory (Experience), an evaluative conscience (Evaluator), and a reflective mind (Self-reflection) that learns from both internal and external critiques to guide behavior (Actor).
* **Purpose**: The overall goal is to create an agent that can **adapt and improve over time**. By reflecting on past actions and storing lessons as experience, the agent aims to make better decisions in future interactions with its environment, demonstrating a form of meta-cognition or learning to learn.