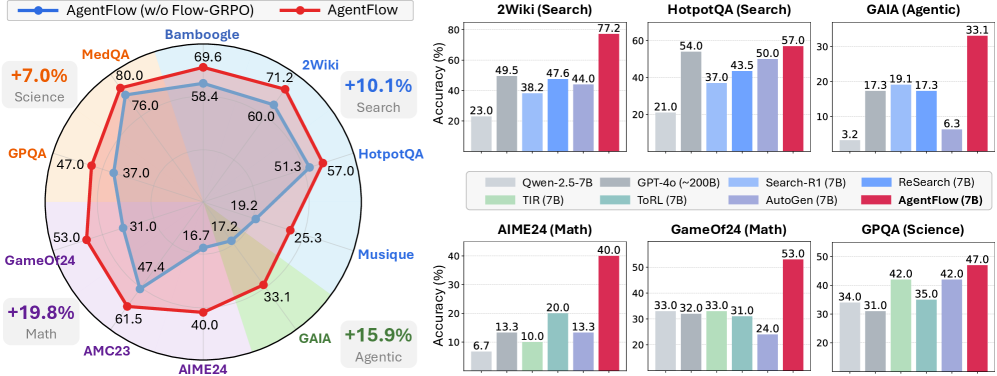
## Chart/Diagram Type: Performance Comparison Chart
### Overview
The image presents a performance comparison of different language models on various tasks. It includes a radar chart comparing "AgentFlow" and "AgentFlow (w/o Flow-GRPO)" across several tasks, and bar charts showing the performance of different models on specific tasks like 2Wiki (Search), HotpotQA (Search), GAIA (Agentic), AIME24 (Math), GameOf24 (Math), and GPQA (Science). The performance metric used is accuracy (%).
### Components/Axes
**Radar Chart:**
* **Title:** Comparison of AgentFlow and AgentFlow (w/o Flow-GRPO)
* **Data Series:**
* AgentFlow (Red Line)
* AgentFlow (w/o Flow-GRPO) (Blue Line)
* **Categories (Spokes):**
* Bamboogle
* MedQA
* GPQA
* GameOf24
* AMC23
* AIME24
* GAIA
* Musique
* HotpotQA
* 2Wiki
* **Values:** Accuracy scores are plotted along each spoke.
**Bar Charts:**
* **Y-axis:** Accuracy (%) ranging from 0 to 80 (varies by chart).
* **X-axis:** Different language models.
* **Legend (located below the bar charts):**
* Qwen-2.5-7B (Light Gray)
* TIR (7B) (Light Green)
* Search-R1 (7B) (Light Blue)
* AutoGen (7B) (Light Purple)
* GPT-4o (~200B) (Green)
* ToRL (7B) (Blue)
* ReSearch (7B) (Purple)
* AgentFlow (7B) (Red)
### Detailed Analysis
**Radar Chart:**
* **AgentFlow (Red):**
* Bamboogle: 69.6
* MedQA: 80.0
* GPQA: 47.0
* GameOf24: 53.0
* AMC23: 61.5
* AIME24: 40.0
* GAIA: 33.1
* Musique: 25.3
* HotpotQA: 57.0
* 2Wiki: 71.2
* **AgentFlow (w/o Flow-GRPO) (Blue):**
* Bamboogle: 58.4
* MedQA: 76.0
* GPQA: 37.0
* GameOf24: 31.0
* AMC23: 47.4
* AIME24: 16.7
* GAIA: 17.2
* Musique: 19.2
* HotpotQA: 51.3
* 2Wiki: 60.0
**Bar Charts:**
* **2Wiki (Search):**
* Qwen-2.5-7B: 23.0%
* GPT-4o (~200B): 49.5%
* Search-R1 (7B): 38.2%
* ToRL (7B): 47.6%
* AutoGen (7B): 44.0%
* AgentFlow (7B): 77.2%
* **HotpotQA (Search):**
* Qwen-2.5-7B: 21.0%
* GPT-4o (~200B): 54.0%
* Search-R1 (7B): 37.0%
* ToRL (7B): 43.5%
* AutoGen (7B): 50.0%
* AgentFlow (7B): 57.0%
* **GAIA (Agentic):**
* Qwen-2.5-7B: 3.2%
* GPT-4o (~200B): 17.3%
* Search-R1 (7B): 19.1%
* ToRL (7B): 17.3%
* AutoGen (7B): 6.3%
* AgentFlow (7B): 33.1%
* **AIME24 (Math):**
* Qwen-2.5-7B: 6.7%
* GPT-4o (~200B): 13.3%
* Search-R1 (7B): 10.0%
* ToRL (7B): 13.3%
* AgentFlow (7B): 40.0%
* **GameOf24 (Math):**
* Qwen-2.5-7B: 33.0%
* GPT-4o (~200B): 32.0%
* TIR (7B): 33.0%
* ToRL (7B): 31.0%
* AgentFlow (7B): 53.0%
* AutoGen (7B): 24.0%
* **GPQA (Science):**
* Qwen-2.5-7B: 34.0%
* GPT-4o (~200B): 42.0%
* TIR (7B): 31.0%
* ToRL (7B): 42.0%
* AutoGen (7B): 35.0%
* AgentFlow (7B): 47.0%
### Key Observations
* AgentFlow consistently outperforms AgentFlow (w/o Flow-GRPO) across all tasks in the radar chart.
* AgentFlow (7B) significantly outperforms other models in 2Wiki (Search), HotpotQA (Search), GAIA (Agentic), AIME24 (Math), and GameOf24 (Math).
* GPT-4o (~200B) shows competitive performance, often being the second-best performing model.
* The performance of different models varies significantly across different tasks.
### Interpretation
The data suggests that AgentFlow benefits significantly from the "Flow-GRPO" component, as evidenced by its superior performance compared to the version without it. AgentFlow (7B) demonstrates strong capabilities across a diverse set of tasks, indicating its potential as a versatile language model. The performance differences between models highlight the importance of model architecture and training data for specific tasks. The radar chart provides a holistic view of AgentFlow's strengths and weaknesses relative to its variant, while the bar charts offer a detailed comparison against other models on individual tasks. The "+X.X%" annotations near the radar chart indicate the percentage improvement of AgentFlow over AgentFlow (w/o Flow-GRPO) for specific categories (Science, Search, Math, Agentic).