TECHNICAL ASSET FINGERPRINT
5eb361f3369ba00eef057810
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.5-flash-free VERSION 1
RUNTIME: google-free/gemini-2.5-flash
INTEL_VERIFIED
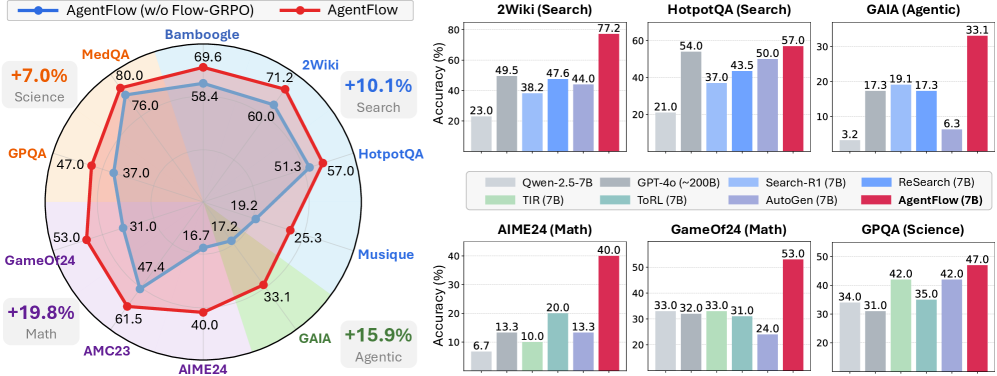
## Mixed Chart Analysis: AgentFlow Performance Across Diverse Tasks
### Overview
The image presents a comparative analysis of "AgentFlow" performance against a baseline "AgentFlow (w/o Flow-GRPO)" and several other models across various tasks. The left side features a radar chart illustrating the relative performance of two AgentFlow variants across ten distinct tasks, grouped into four broader categories (Science, Search, Agentic, Math), with aggregated percentage improvements. The right side displays six individual bar charts, providing a more granular comparison of "AgentFlow (7B)" against up to seven other models (Qwen-2.5-7B, GPT-4o (~200B), TIR (7B), ToRL (7B), Search-R1 (7B), ReSearch (7B), AutoGen (7B)) for specific tasks, showing "Accuracy (%)".
### Components/Axes
**Left Side: Radar Chart**
* **Title:** Implicitly comparing "AgentFlow (w/o Flow-GRPO)" and "AgentFlow".
* **Legend (Top-Left):**
* Blue line with circular markers: "AgentFlow (w/o Flow-GRPO)"
* Red line with circular markers: "AgentFlow"
* **Radial Axes/Categories (Clockwise from top):**
* Bamboogle
* 2Wiki
* HotpotQA
* Musique
* GAIA
* AIME24
* AMC23
* GameOf24
* GPQA
* MedQA
* **Radial Scale:** Concentric circles represent increasing performance values, likely percentages. The innermost circle represents 0, and the outermost visible circle corresponds to values up to 80.0.
* **Additional Labels:**
* Top-left, near MedQA: "+7.0% Science"
* Top-right, near 2Wiki: "+10.1% Search"
* Bottom-right, near GAIA: "+15.9% Agentic"
* Bottom-left, near GameOf24: "+19.8% Math"
**Right Side: Bar Charts**
* **Common Y-axis (Left side of each bar chart):** "Accuracy (%)"
* **Common Legend (Positioned centrally, below the top row of bar charts):**
* Light Gray bar: Qwen-2.5-7B
* Dark Gray bar: GPT-4o (~200B)
* Light Green bar: TIR (7B)
* Light Blue bar: ToRL (7B)
* Medium Blue bar: Search-R1 (7B)
* Dark Blue bar: ReSearch (7B)
* Light Purple bar: AutoGen (7B)
* Red bar: AgentFlow (7B)
* **Individual Chart Titles:**
* Top-left: 2Wiki (Search)
* Top-middle: HotpotQA (Search)
* Top-right: GAIA (Agentic)
* Bottom-left: AIME24 (Math)
* Bottom-middle: GameOf24 (Math)
* Bottom-right: GPQA (Science)
### Detailed Analysis
**Radar Chart (Left Side)**
The radar chart visually compares the performance of "AgentFlow" (red line) against "AgentFlow (w/o Flow-GRPO)" (blue line) across ten tasks. The red line consistently encloses or significantly extends beyond the blue line, indicating superior performance for "AgentFlow" in all categories.
* **AgentFlow (w/o Flow-GRPO) (Blue Line):**
* MedQA: 76.0
* GPQA: 37.0
* GameOf24: 31.0
* AMC23: 47.4
* AIME24: 16.7
* GAIA: 17.2
* Musique: 25.3
* HotpotQA: 51.3
* 2Wiki: 60.0
* Bamboogle: 58.4
* **AgentFlow (Red Line):**
* MedQA: 80.0
* GPQA: 47.0
* GameOf24: 53.0
* AMC23: 61.5
* AIME24: 40.0
* GAIA: 33.1
* Musique: 33.1
* HotpotQA: 57.0
* 2Wiki: 71.2
* Bamboogle: 69.6
* **Aggregated Improvements:**
* **Science:** +7.0% (associated with MedQA, GPQA, Bamboogle)
* **Search:** +10.1% (associated with 2Wiki, HotpotQA)
* **Agentic:** +15.9% (associated with Musique, GAIA)
* **Math:** +19.8% (associated with AIME24, AMC23, GameOf24)
**Bar Charts (Right Side)**
Each bar chart shows the "Accuracy (%)" for different models on a specific task. The red bar, representing "AgentFlow (7B)", consistently shows the highest performance in all six tasks.
1. **2Wiki (Search)**
* Trend: AgentFlow (7B) is significantly higher than all other models.
* Qwen-2.5-7B (light gray): 23.0
* GPT-4o (~200B) (dark gray): 49.5
* ToRL (7B) (light blue): 38.2
* Search-R1 (7B) (medium blue): 47.6
* AutoGen (7B) (light purple): 44.0
* AgentFlow (7B) (red): 77.2
2. **HotpotQA (Search)**
* Trend: AgentFlow (7B) is the highest, with GPT-4o and AutoGen as the next best performers.
* Qwen-2.5-7B (light gray): 21.0
* GPT-4o (~200B) (dark gray): 54.0
* ToRL (7B) (light blue): 37.0
* Search-R1 (7B) (medium blue): 43.5
* AutoGen (7B) (light purple): 50.0
* AgentFlow (7B) (red): 57.0
3. **GAIA (Agentic)**
* Trend: AgentFlow (7B) shows a substantial lead over all other models, which perform significantly lower.
* Qwen-2.5-7B (light gray): 3.2
* GPT-4o (~200B) (dark gray): 17.3
* ToRL (7B) (light blue): 19.1
* Search-R1 (7B) (medium blue): 17.3
* ReSearch (7B) (dark blue): 6.3
* AutoGen (7B) (light purple): Not present (The dark blue bar for ReSearch (7B) is the 6th bar, with value 6.3. The light purple bar for AutoGen (7B) is not present in this chart.)
* AgentFlow (7B) (red): 33.1
4. **AIME24 (Math)**
* Trend: AgentFlow (7B) is significantly superior, with ToRL (7B) being the second-best but still far behind.
* Qwen-2.5-7B (light gray): 6.7
* GPT-4o (~200B) (dark gray): 13.3
* TIR (7B) (light green): 10.0
* ToRL (7B) (light blue): 20.0
* AutoGen (7B) (light purple): 13.3
* AgentFlow (7B) (red): 40.0
5. **GameOf24 (Math)**
* Trend: AgentFlow (7B) performs substantially better than other models, which are clustered in a lower range.
* Qwen-2.5-7B (light gray): 33.0
* GPT-4o (~200B) (dark gray): 32.0
* TIR (7B) (light green): 33.0
* ToRL (7B) (light blue): 31.0
* AutoGen (7B) (light purple): 24.0
* AgentFlow (7B) (red): 53.0
6. **GPQA (Science)**
* Trend: AgentFlow (7B) achieves the highest accuracy, followed by TIR (7B) and Search-R1 (7B).
* Qwen-2.5-7B (light gray): 34.0
* GPT-4o (~200B) (dark gray): 31.0
* TIR (7B) (light green): 42.0
* ToRL (7B) (light blue): 35.0
* Search-R1 (7B) (medium blue): 42.0
* AgentFlow (7B) (red): 47.0
### Key Observations
* **Consistent Superiority of AgentFlow:** In both the radar chart and all six bar charts, "AgentFlow" (red line/bar) consistently outperforms its baseline "AgentFlow (w/o Flow-GRPO)" and all other compared models.
* **Impact of Flow-GRPO:** The radar chart clearly demonstrates that the "Flow-GRPO" component significantly boosts AgentFlow's performance across all ten tasks, as the red line (with Flow-GRPO) is always outside the blue line (without Flow-GRPO).
* **Significant Gains in Math and Agentic Tasks:** The aggregated percentage improvements highlight that "AgentFlow" achieves its largest gains over the baseline in Math tasks (+19.8%) and Agentic tasks (+15.9%).
* **Strong Performance in Search Tasks:** AgentFlow shows substantial leads in 2Wiki (77.2%) and HotpotQA (57.0%) compared to other models, with a +10.1% aggregated improvement in Search tasks.
* **Varied Competitor Performance:** While AgentFlow is consistently best, the performance of other models varies. GPT-4o (~200B) often performs well among the non-AgentFlow models, particularly in search tasks (e.g., 49.5% in 2Wiki, 54.0% in HotpotQA).
* **Large Gaps in Challenging Tasks:** In tasks like GAIA (Agentic) and AIME24 (Math), AgentFlow's lead is particularly pronounced, suggesting its approach is highly effective for these more complex problem types. For instance, in GAIA, AgentFlow scores 33.1% while the next best is ToRL (7B) at 19.1%.
### Interpretation
The data strongly suggests that "AgentFlow" is a highly effective system, and its "Flow-GRPO" component is critical for its superior performance. The radar chart provides a holistic view, emphasizing the broad applicability and consistent improvement across diverse task categories, including Science, Search, Agentic, and Math. The aggregated percentage increases further quantify these improvements, highlighting the most impactful areas.
The bar charts provide crucial validation by comparing "AgentFlow (7B)" against a range of other established and competitive models. The consistent top performance of "AgentFlow (7B)" across all six detailed tasks (2Wiki, HotpotQA, GAIA, AIME24, GameOf24, GPQA) indicates its robustness and generalizability. The significant performance gaps, especially in tasks like GAIA and AIME24, imply that "AgentFlow" might possess unique capabilities or a more effective strategy for handling the complexities inherent in agentic and mathematical reasoning tasks. The fact that "AgentFlow (7B)" often doubles or triples the accuracy of other 7B models (e.g., in AIME24) and even outperforms much larger models like GPT-4o (~200B) in several instances (e.g., 2Wiki, GAIA, AIME24, GameOf24), underscores its efficiency and effectiveness.
Overall, the image serves as compelling evidence for the efficacy of the "AgentFlow" system, particularly when augmented with "Flow-GRPO," positioning it as a leading solution for a wide array of challenging AI benchmarks. The data implies that the "Flow-GRPO" mechanism likely contributes to better task understanding, planning, or execution, leading to these substantial performance gains.
DECODING INTELLIGENCE...