## Composite Performance Analysis: AgentFlow vs. Baseline Models
### Overview
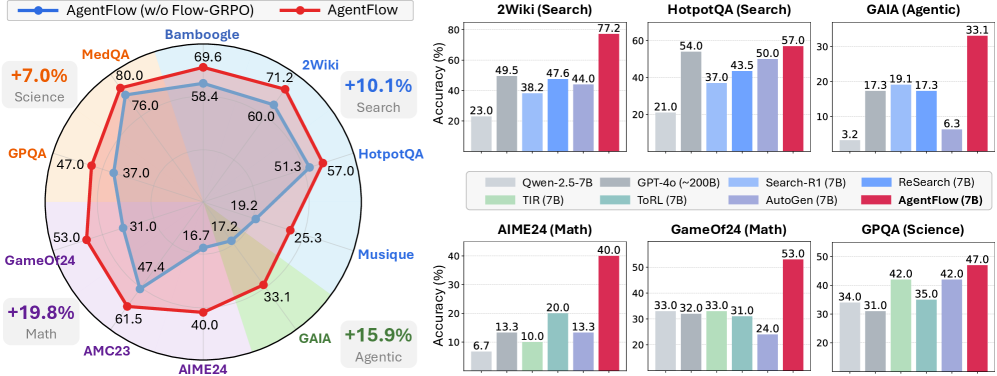
The image is a composite technical figure comparing the performance of an AI system named "AgentFlow" against several baseline models across a variety of reasoning and knowledge-intensive tasks. It consists of two main sections: a radar chart on the left and a grid of six bar charts on the right. The overall theme is a performance benchmark, highlighting AgentFlow's improvements in specific domains.
### Components/Axes
**1. Left Section: Radar Chart**
* **Title/Legend:** Located at the top. Two series are plotted:
* `AgentFlow (w/o Flow-GRPO)` - Blue line with circular markers.
* `AgentFlow` - Red line with circular markers.
* **Axes (Tasks):** The chart has 10 radial axes, each representing a different benchmark task. Labels are placed around the perimeter:
* `MedQA` (Top)
* `Bamboogle`
* `2Wiki`
* `HotpotQA`
* `Musique`
* `GAIA` (Bottom Right)
* `AIME24`
* `AMC23`
* `GameOf24`
* `GPQA` (Left)
* **Highlighted Improvements:** Three text boxes with percentage gains are placed around the chart:
* Top-Left: `+7.0% Science` (near MedQA/GPQA)
* Top-Right: `+10.1% Search` (near 2Wiki/HotpotQA)
* Bottom-Left: `+19.8% Math` (near GameOf24/AMC23/AIME24)
* Bottom-Right: `+15.9% Agentic` (near GAIA/Musique)
**2. Right Section: Bar Chart Grid (6 Charts)**
* **Common Legend:** Located below the top row of charts. It defines the color coding for all bar charts:
* Light Gray: `Qwen-2.5-7B`
* Dark Gray: `GPT-4o (~200B)`
* Light Blue: `Search-R1 (7B)`
* Medium Blue: `ReSearch (7B)`
* Light Green: `TIR (7B)`
* Teal: `ToRL (7B)`
* Purple: `AutoGen (7B)`
* **Red: `AgentFlow (7B)`** (This is the primary subject of comparison).
* **Individual Charts:** Each chart has a title indicating the task and category, and a Y-axis labeled `Accuracy (%)`.
### Detailed Analysis
**A. Radar Chart Data Points (Approximate Values)**
The red line (AgentFlow) generally encloses the blue line (AgentFlow w/o Flow-GRPO), indicating superior performance across all tasks.
* **MedQA:** AgentFlow ~80.0, w/o Flow-GRPO ~76.0
* **Bamboogle:** AgentFlow ~69.6, w/o Flow-GRPO ~58.4
* **2Wiki:** AgentFlow ~71.2, w/o Flow-GRPO ~60.0
* **HotpotQA:** AgentFlow ~57.0, w/o Flow-GRPO ~51.3
* **Musique:** AgentFlow ~25.3, w/o Flow-GRPO ~19.2
* **GAIA:** AgentFlow ~33.1, w/o Flow-GRPO ~17.2
* **AIME24:** AgentFlow ~40.0, w/o Flow-GRPO ~16.7
* **AMC23:** AgentFlow ~61.5, w/o Flow-GRPO ~47.4
* **GameOf24:** AgentFlow ~53.0, w/o Flow-GRPO ~31.0
* **GPQA:** AgentFlow ~47.0, w/o Flow-GRPO ~37.0
**B. Bar Chart Data Points (Accuracy %)**
* **Top-Left: 2Wiki (Search)**
* Qwen-2.5-7B: 23.0
* GPT-4o: 49.5
* Search-R1: 38.2
* ReSearch: 47.6
* **AgentFlow: 77.2** (Highest by a large margin)
* **Top-Center: HotpotQA (Search)**
* Qwen-2.5-7B: 21.0
* GPT-4o: 54.0
* Search-R1: 37.0
* ReSearch: 43.5
* AutoGen: 50.0
* **AgentFlow: 57.0** (Highest)
* **Top-Right: GAIA (Agentic)**
* Qwen-2.5-7B: 3.2
* GPT-4o: 17.3
* Search-R1: 19.1
* ReSearch: 17.3
* AutoGen: 6.3
* **AgentFlow: 33.1** (Highest, more than double the next best)
* **Bottom-Left: AIME24 (Math)**
* Qwen-2.5-7B: 6.7
* GPT-4o: 13.3
* TIR: 10.0
* ToRL: 20.0
* AutoGen: 13.3
* **AgentFlow: 40.0** (Highest, double the next best)
* **Bottom-Center: GameOf24 (Math)**
* Qwen-2.5-7B: 33.0
* GPT-4o: 32.0
* TIR: 33.0
* ToRL: 31.0
* AutoGen: 24.0
* **AgentFlow: 53.0** (Highest, significant lead)
* **Bottom-Right: GPQA (Science)**
* Qwen-2.5-7B: 34.0
* GPT-4o: 31.0
* TIR: 42.0
* ToRL: 35.0
* AutoGen: 42.0
* **AgentFlow: 47.0** (Highest)
### Key Observations
1. **Consistent Superiority:** AgentFlow (red bar/line) achieves the highest accuracy in every single task presented across both the radar and bar charts.
2. **Domain-Specific Strengths:** The most dramatic performance gaps are in the **Math** (AIME24, GameOf24) and **Agentic** (GAIA) categories, where AgentFlow often doubles or more than doubles the score of the next-best model.
3. **Search Task Dominance:** In search-oriented tasks (2Wiki, HotpotQA), AgentFlow shows a clear lead, though the margin is slightly smaller than in math/agentic tasks.
4. **Impact of Flow-GRPO:** The radar chart demonstrates that the full AgentFlow system (red) consistently outperforms its ablated version without Flow-GRPO (blue), confirming the contribution of this component.
5. **Model Scale Context:** The bar charts compare the 7B-parameter AgentFlow primarily against other 7B models and the much larger GPT-4o (~200B). AgentFlow outperforms both categories.
### Interpretation
This composite figure serves as a strong empirical argument for the effectiveness of the AgentFlow architecture. The data suggests that AgentFlow is not just marginally better but represents a significant step forward, particularly in tasks requiring **multi-step reasoning (Math)** and **autonomous tool/agent use (Agentic tasks like GAIA)**. Its consistent lead over both similarly sized models and a much larger frontier model (GPT-4o) indicates architectural efficiencies rather than brute-force scaling.
The radar chart's "improvement bubbles" (+7.0% Science, +10.1% Search, etc.) frame the narrative, guiding the viewer to see the gains as domain-specific breakthroughs. The isolation of the "Flow-GRPO" component in the radar chart provides an ablation study, suggesting this specific technique is a key driver of the overall performance gain.
**Language Note:** The image contains English text exclusively for labels, legends, and data. The category labels "Science", "Search", "Math", and "Agentic" are in English.