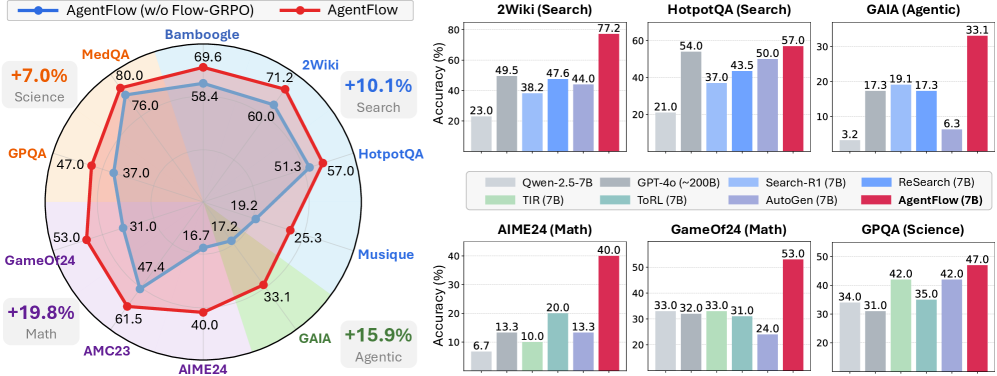
## Radar Chart: AgentFlow Performance Comparison (w/o Flow-GRPO vs. AgentFlow)
### Overview
A radar chart comparing two configurations of AgentFlow across multiple datasets. The blue line represents "AgentFlow (w/o Flow-GRPO)" and the red line represents "AgentFlow". The chart includes labeled axes for datasets and percentage-based performance metrics.
### Components/Axes
- **Axes**:
- Labeled with datasets: Bambooogle, 2Wiki, HotpotQA, Musiq, GameOf24, AMC23, AIME24, GAIA.
- Radial scale: 0% to 80% (approximate).
- **Legend**:
- Blue: AgentFlow (w/o Flow-GRPO)
- Red: AgentFlow
- Positioned at the top-left of the radar chart.
### Detailed Analysis
- **Blue Line (AgentFlow w/o Flow-GRPO)**:
- Values: 69.6 (Bambooogle), 71.2 (2Wiki), 57.0 (HotpotQA), 31.0 (Musiq), 47.4 (GameOf24), 61.5 (AMC23), 40.0 (AIME24), 51.3 (GAIA).
- Trend: Peaks at Bambooogle (69.6%) and declines toward Musiq (31.0%).
- **Red Line (AgentFlow)**:
- Values: 80.0 (Bambooogle), 77.2 (2Wiki), 57.0 (HotpotQA), 25.3 (Musiq), 61.5 (AMC23), 40.0 (AIME24), 51.3 (GAIA).
- Trend: Consistently higher than the blue line across all datasets, with a notable drop at Musiq (25.3%).
### Key Observations
- **Performance Gains**:
- +7.0% improvement in Science (MedQA).
- +10.1% improvement in Search (2Wiki).
- +19.8% improvement in Math (AIME24).
- +15.9% improvement in Agentic tasks (GAIA).
- **Outliers**:
- Musiq dataset shows the largest drop for both configurations (blue: 31.0% → red: 25.3%).
### Interpretation
The radar chart demonstrates that AgentFlow with Flow-GRPO (red line) outperforms the baseline AgentFlow (blue line) across all datasets, with the most significant gains in Math (+19.8%) and Search (+10.1%). The Musiq dataset is an outlier, where both configurations underperform, suggesting potential domain-specific limitations. The annotations highlight AgentFlow's adaptability across diverse tasks, particularly in computational and agentic reasoning.
---
## Bar Charts: Model Performance Across Tasks
### Components/Axes
- **Tasks**:
- 2Wiki (Search), HotpotQA (Search), GAIA (Agentic), AIME24 (Math), GameOf24 (Math), GPQA (Science).
- **Models**:
- Qwen-2.5-7B (gray), GPT-4o (~200B) (dark gray), Search-R1 (7B) (light blue), ReSearch (7B) (blue), ToRL (7B) (teal), AutoGen (7B) (purple), AgentFlow (7B) (red).
- **Legend**: Positioned at the bottom-right of the bar charts.
### Detailed Analysis
- **2Wiki (Search)**:
- AgentFlow (7B): 77.2% (highest).
- Qwen-2.5-7B: 49.5%.
- GPT-4o: 38.2%.
- **HotpotQA (Search)**:
- AgentFlow (7B): 57.0%.
- GPT-4o: 54.0%.
- Search-R1: 37.0%.
- **GAIA (Agentic)**:
- AgentFlow (7B): 33.1%.
- ReSearch: 17.3%.
- AutoGen: 6.3%.
- **AIME24 (Math)**:
- AgentFlow (7B): 40.0%.
- ToRL: 20.0%.
- Qwen-2.5-7B: 6.7%.
- **GameOf24 (Math)**:
- AgentFlow (7B): 53.0%.
- GPT-4o: 33.0%.
- AutoGen: 24.0%.
- **GPQA (Science)**:
- AgentFlow (7B): 47.0%.
- ReSearch: 42.0%.
- ToRL: 35.0%.
### Key Observations
- **AgentFlow Dominance**:
- AgentFlow (7B) consistently achieves the highest accuracy across all tasks.
- Notable gaps:
- 2Wiki: 77.2% (AgentFlow) vs. 49.5% (Qwen-2.5-7B).
- AIME24: 40.0% (AgentFlow) vs. 6.7% (Qwen-2.5-7B).
- **Model Specialization**:
- GPT-4o excels in Search tasks (54.0% in HotpotQA).
- ReSearch and ToRL perform moderately in Search and Science tasks.
### Interpretation
AgentFlow (7B) demonstrates superior performance across diverse tasks, particularly in Search and Math, where it outperforms larger models like GPT-4o. The GAIA task highlights AgentFlow's edge in agentic reasoning, while ReSearch and ToRL show promise in Search and Science. The stark contrast in AIME24 (Math) underscores AgentFlow's computational reasoning capabilities. These results suggest that AgentFlow's architecture, possibly enhanced by Flow-GRPO, enables efficient task adaptation and accuracy gains.