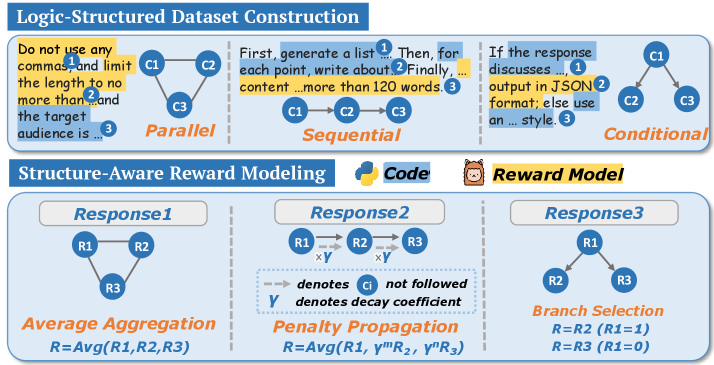
\n
## Diagram: Logic-Structured Dataset Construction & Structure-Aware Reward Modeling
### Overview
The image presents a diagram illustrating two key components of a system: Logic-Structured Dataset Construction and Structure-Aware Reward Modeling. The top section details different approaches to dataset construction (Parallel, Sequential, Conditional), while the bottom section outlines three reward modeling strategies (Average Aggregation, Penalty Propagation, Branch Selection). The diagram uses tree-like structures and arrows to represent relationships and flows within each component.
### Components/Axes
The diagram is divided into two main sections: "Logic-Structured Dataset Construction" (top) and "Structure-Aware Reward Modeling" (bottom). Each section contains three sub-diagrams representing different approaches. Each sub-diagram features nodes (C1, C2, C3 or R1, R2, R3) connected by lines or arrows. There are also text labels describing each approach and associated formulas. Icons for "Code" and a "Reward Model" (represented by a bear) are present. Numbered circles (1, 2, 3) are used to indicate steps or points within the descriptions.
### Detailed Analysis or Content Details
**Logic-Structured Dataset Construction:**
* **Parallel:** A diagram with three nodes labeled C1, C2, and C3. All nodes are connected to a central, unlabelled node. The text reads: "Do not use any commas, and limit the length to no more than… and the target audience is…". Numbered points: 1. "First, generate a list", 2. "Then, for each point, write about…", 3. "Finally, content…more than 120 words."
* **Sequential:** A diagram with three nodes labeled C1, C2, and C3. Nodes are connected sequentially: C1 -> C2 -> C3. The text reads: "If the response discusses… output in JSON format; else use an… style." Numbered points: 1. "First, generate a list", 2. "Then, for each point, write about…", 3. "Finally, content…more than 120 words."
* **Conditional:** A diagram with three nodes labeled C1, C2, and C3. The connections are branching, resembling a decision tree. The text reads: "If the response discusses… output in JSON format; else use an… style." Numbered points: 1. "First, generate a list", 2. "Then, for each point, write about…", 3. "Finally, content…more than 120 words."
**Structure-Aware Reward Modeling:**
* **Average Aggregation:** A tree structure with nodes R1, R2, and R3. R1 connects to R2 and R3. The formula is: "R = Avg(R1, R2, R3)".
* **Penalty Propagation:** A tree structure with nodes R1, R2, and R3. R1 connects to R2 with a solid arrow, and R2 connects to R3 with a dashed arrow. R1 also connects directly to R3 with a dashed arrow. The text includes: "denotes ⊣ not followed" and "γ denotes decay coefficient". The formula is: "R = Avg(R1, γ^R2, γ^R3)".
* **Branch Selection:** A tree structure with nodes R1, R2, and R3. R1 connects to R2 and R3. The text reads: "R = R2 (R1=1) R = R3 (R1=0)".
### Key Observations
* The "Logic-Structured Dataset Construction" section focuses on different ways to organize the creation of a dataset, emphasizing constraints on length and style.
* The "Structure-Aware Reward Modeling" section explores different methods for calculating a reward based on the structure of a response.
* The Penalty Propagation method introduces the concept of a "decay coefficient" (γ), suggesting that rewards diminish as the response deviates from a preferred structure.
* The Branch Selection method uses a binary decision (R1=1 or R1=0) to determine which branch (R2 or R3) receives the reward.
* The numbered points (1, 2, 3) are consistent across the dataset construction methods, suggesting a common workflow.
### Interpretation
This diagram illustrates a system designed to generate and evaluate responses based on a predefined logical structure. The dataset construction methods aim to create data that adheres to specific constraints, while the reward modeling strategies incentivize responses that conform to the desired structure. The use of tree structures and formulas suggests a formal, mathematical approach to both dataset creation and reward calculation. The inclusion of a decay coefficient in the Penalty Propagation method indicates a nuanced approach to reward assignment, where deviations from the ideal structure are penalized. The overall system appears to be geared towards generating structured, concise, and targeted responses, potentially for applications like question answering or dialogue systems. The icons for "Code" and "Reward Model" suggest that this is a system implemented in software, with a clear separation between the code that generates responses and the model that evaluates them. The bear icon for the reward model is likely a playful visual element.