\n
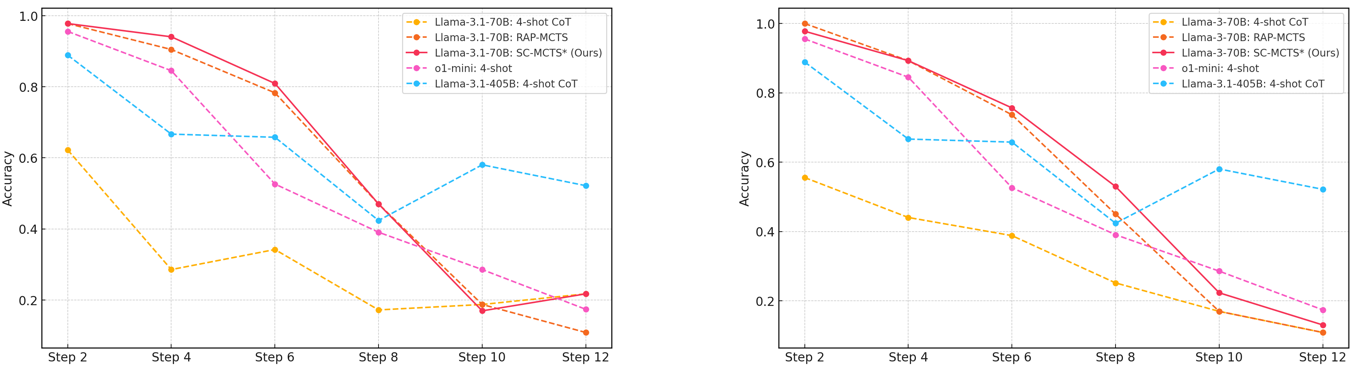
## Line Chart: Accuracy vs. Step for Different Models
### Overview
The image presents two line charts, side-by-side, comparing the accuracy of several language models (Llama-3.1-70B, Llama-3.1-405B, and ol-mini) across different steps (2, 4, 6, 8, 10, and 12). The accuracy is measured on the y-axis, ranging from 0.0 to 1.0, while the step number is on the x-axis. Each line represents a different model or configuration. The charts appear to be evaluating the performance of these models in a multi-step reasoning process.
### Components/Axes
* **Y-axis Label:** "Accuracy" (Scale: 0.0 to 1.0, increments of 0.2)
* **X-axis Label:** "Step" (Markers: 2, 4, 6, 8, 10, 12)
* **Legend (Top-Right of each chart):**
* Llama-3.1-70B: 4-shot CoT (Orange, dashed line)
* Llama-3.1-70B: RAP-MCTS (Yellow, dashed line)
* Llama-3.1-70B: SC-MCTS¹ (Ours) (Red, solid line)
* ol-mini: 4-shot (Pink, dashed line)
* Llama-3.1-405B: 4-shot CoT (Blue, dashed line)
### Detailed Analysis or Content Details
**Chart 1 (Left):**
* **Llama-3.1-70B: 4-shot CoT (Orange):** Starts at approximately 0.9 accuracy at Step 2, decreases steadily to approximately 0.15 at Step 12.
* **Llama-3.1-70B: RAP-MCTS (Yellow):** Starts at approximately 0.8 accuracy at Step 2, decreases to approximately 0.2 at Step 12.
* **Llama-3.1-70B: SC-MCTS¹ (Ours) (Red):** Starts at approximately 0.85 accuracy at Step 2, decreases rapidly to approximately 0.1 at Step 12.
* **ol-mini: 4-shot (Pink):** Starts at approximately 0.7 accuracy at Step 2, decreases sharply to approximately 0.1 at Step 12.
* **Llama-3.1-405B: 4-shot CoT (Blue):** Starts at approximately 0.95 accuracy at Step 2, decreases rapidly to approximately 0.15 at Step 12.
**Chart 2 (Right):**
* **Llama-3.1-70B: 4-shot CoT (Orange):** Starts at approximately 0.9 accuracy at Step 2, decreases steadily to approximately 0.15 at Step 12.
* **Llama-3.1-70B: RAP-MCTS (Yellow):** Starts at approximately 0.8 accuracy at Step 2, decreases to approximately 0.2 at Step 12.
* **Llama-3.1-70B: SC-MCTS¹ (Ours) (Red):** Starts at approximately 0.85 accuracy at Step 2, decreases rapidly to approximately 0.1 at Step 12.
* **ol-mini: 4-shot (Pink):** Starts at approximately 0.7 accuracy at Step 2, decreases sharply to approximately 0.1 at Step 12.
* **Llama-3.1-405B: 4-shot CoT (Blue):** Starts at approximately 0.95 accuracy at Step 2, decreases rapidly to approximately 0.15 at Step 12.
### Key Observations
* All models exhibit a significant decrease in accuracy as the step number increases. This suggests that the models struggle with maintaining performance over multiple reasoning steps.
* Llama-3.1-405B: 4-shot CoT consistently starts with the highest accuracy in both charts.
* The "SC-MCTS¹ (Ours)" model (red line) shows a relatively steep decline in accuracy compared to other models.
* The two charts are nearly identical, suggesting the results are consistent across different runs or datasets.
### Interpretation
The data suggests that while larger models (Llama-3.1-405B) may initially perform better, all models experience a substantial drop in accuracy as the number of reasoning steps increases. This indicates a limitation in the models' ability to maintain coherence and accuracy over extended reasoning chains. The rapid decline of the "SC-MCTS¹ (Ours)" model suggests that this particular approach may not scale well with increasing step numbers, despite potentially showing promise in initial steps. The consistent trend across both charts reinforces the robustness of the findings. The "1" superscript on "SC-MCTS¹" suggests a version or variant of the model, and further investigation would be needed to understand the specific differences. The consistent decline in accuracy across all models highlights the ongoing challenge of building language models capable of complex, multi-step reasoning.