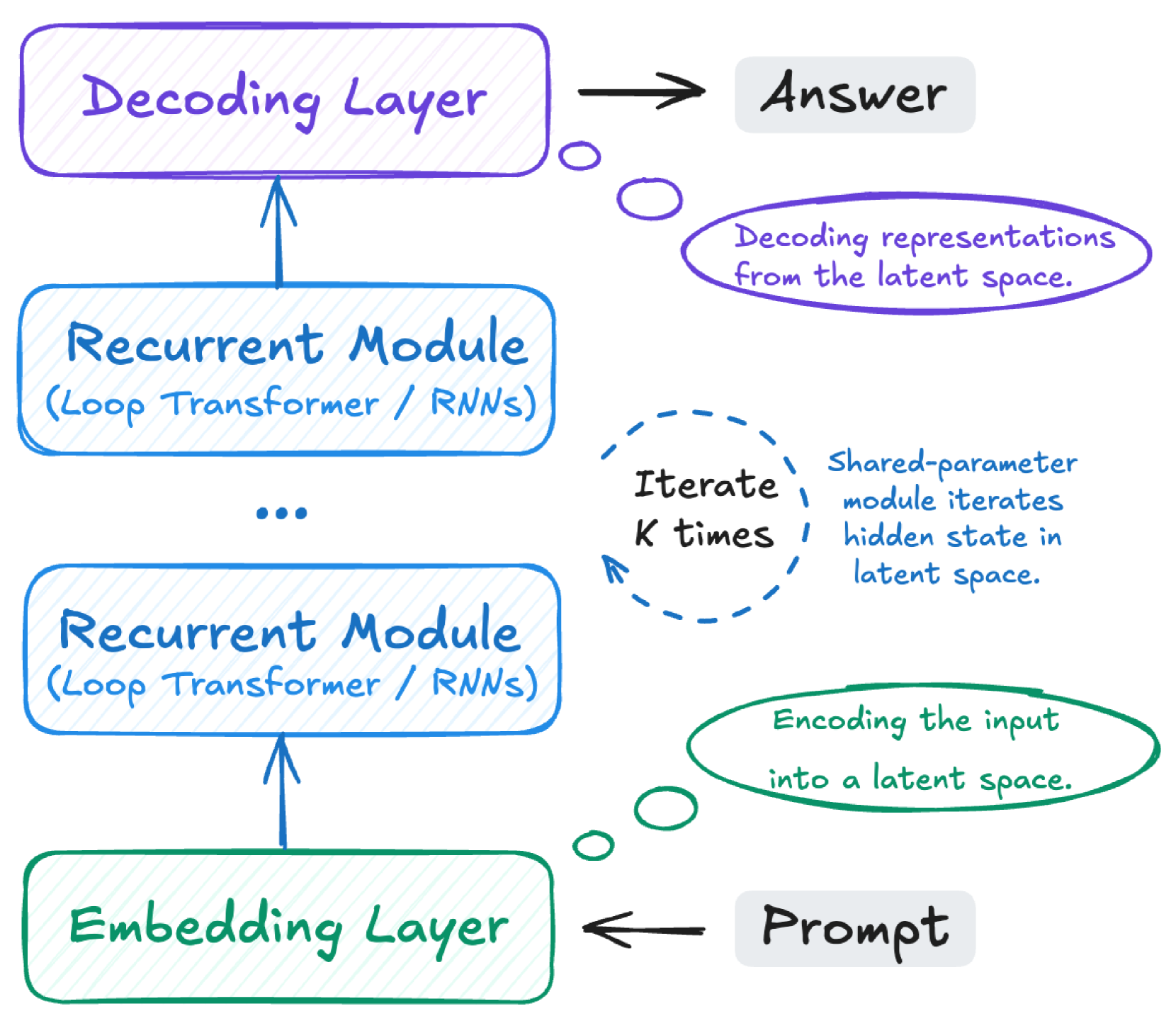
## Diagram: Neural Network Architecture for Sequence Processing
### Overview
The diagram illustrates a neural network architecture for processing sequential data, showing the flow from input (Prompt) to output (Answer). It includes an Embedding Layer, multiple Recurrent Modules, and a Decoding Layer, with annotations explaining their functions and interactions.
### Components/Axes
1. **Embedding Layer** (Green): Encodes the input prompt into a latent space.
2. **Recurrent Module** (Blue): Contains either Loop Transformers or RNNs. Two instances are shown, with a dashed circular arrow indicating iteration.
3. **Decoding Layer** (Purple): Decodes representations from the latent space to generate the answer.
4. **Annotations**:
- "Shared-parameter module iterates hidden state in latent space" (dashed blue circle).
- "Iterate K times" (dashed blue arrow).
- "Decoding representations from the latent space" (purple oval).
- "Encoding the input into a latent space" (green oval).
### Detailed Analysis
- **Flow**:
- The process starts with a **Prompt**, which is encoded by the **Embedding Layer** into a latent space.
- The latent representation is passed through **Recurrent Modules** (Loop Transformers/RNNs), which iterate **K times** using a shared-parameter mechanism to refine the hidden state.
- The processed latent state is then fed into the **Decoding Layer**, which decodes it to produce the **Answer**.
- **Key Technical Details**:
- **Recurrent Modules**: Explicitly labeled as supporting Loop Transformers or RNNs, emphasizing flexibility in sequence modeling.
- **Shared-Parameter Iteration**: The dashed blue arrow and oval highlight that the same module parameters are reused across iterations, optimizing computational efficiency.
- **Latent Space**: Both encoding (green oval) and decoding (purple oval) operations occur within this shared latent space, suggesting a bottleneck for representation learning.
### Key Observations
1. **Iterative Refinement**: The Recurrent Modules' repeated processing (K times) implies a focus on capturing long-range dependencies or temporal patterns.
2. **Shared Parameters**: The shared-parameter design reduces redundancy, a common optimization in transformer-based models.
3. **Modularity**: The architecture separates embedding, recurrence, and decoding into distinct layers, aligning with standard NLP pipeline design.
### Interpretation
This architecture resembles a hybrid of recurrent and transformer-based models, optimized for sequential data. The shared-parameter iteration in the latent space suggests a focus on efficiency and scalability, while the explicit separation of embedding and decoding layers mirrors encoder-decoder frameworks (e.g., in machine translation). The use of Loop Transformers/RNNs indicates adaptability to different sequence modeling paradigms. The diagram emphasizes the importance of latent space manipulation, where both encoding and decoding occur, highlighting the model's ability to abstract and reconstruct information.