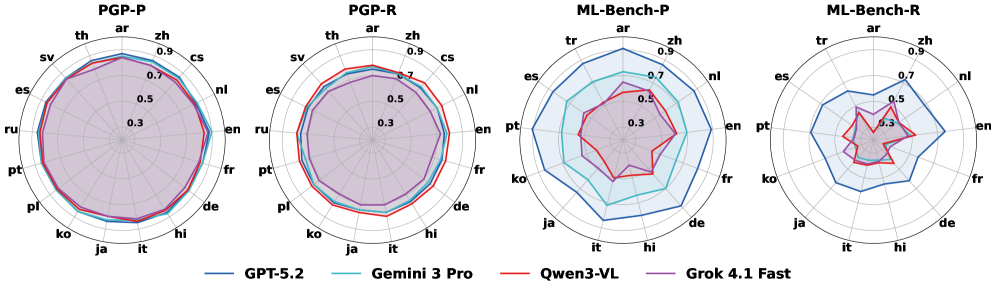
# Technical Data Extraction: Multilingual Model Performance Radar Charts
This document provides a comprehensive extraction of data from four radar (spider) charts comparing the performance of four AI models across various languages and benchmarks.
## 1. Metadata and Global Legend
* **Chart Type:** Radar Charts (4 sub-plots)
* **Data Series (Models):**
* **GPT-5.2** (Dark Blue line)
* **Gemini 3 Pro** (Light Blue/Cyan line)
* **Qwen3-VL** (Red line)
* **Grok 4.1 Fast** (Purple line)
* **Axis Scale:** Radial scale from 0.3 to 0.9 (increments of 0.2 marked: 0.3, 0.5, 0.7, 0.9).
* **Legend Location:** Bottom center of the image.
---
## 2. Component Analysis
The image is segmented into four distinct benchmarks, each evaluating performance across a set of languages (represented by ISO 639-1 codes).
### A. PGP-P (First Chart)
* **Languages (16):** ar, zh, cs, nl, en, fr, de, hi, it, ja, ko, pl, pt, ru, es, sv, th.
* **Trend Observation:** All models show high, stable performance across all languages, forming nearly perfect circles near the 0.8 - 0.9 range.
* **Model Rankings:**
* **GPT-5.2:** Highest performance, consistently touching or exceeding the 0.8 mark.
* **Gemini 3 Pro & Qwen3-VL:** Closely overlapping GPT-5.2.
* **Grok 4.1 Fast:** Slightly lower than the others, particularly in the 'th' to 'cs' sector, but still above 0.7.
### B. PGP-R (Second Chart)
* **Languages (16):** ar, zh, cs, nl, en, fr, de, hi, it, ja, ko, pl, pt, ru, es, sv, th.
* **Trend Observation:** Similar to PGP-P, performance is high and stable (0.7 - 0.9 range), though slightly more variance is visible between models compared to PGP-P.
* **Model Rankings:**
* **GPT-5.2:** Leading performance (~0.85).
* **Qwen3-VL:** Very close to GPT-5.2.
* **Gemini 3 Pro:** Slightly below the top two.
* **Grok 4.1 Fast:** Consistently the innermost line, hovering around the 0.7 mark.
### C. ML-Bench-P (Third Chart)
* **Languages (14):** ar, zh, nl, en, fr, de, hi, it, ja, ko, pt, es, tr.
* **Trend Observation:** Significant performance divergence. GPT-5.2 maintains a large, relatively stable outer ring, while other models show significant drops in specific languages.
* **Model Rankings:**
* **GPT-5.2:** Dominant (0.8 - 0.9 range).
* **Gemini 3 Pro:** Second place, showing a similar shape but smaller (~0.6 - 0.7 range).
* **Qwen3-VL & Grok 4.1 Fast:** Significant performance degradation, dropping toward the 0.4 - 0.5 range, with Qwen3-VL showing a particularly jagged profile (lower in 'hi', 'it', 'ja').
### D. ML-Bench-R (Fourth Chart)
* **Languages (14):** ar, zh, nl, en, fr, de, hi, it, ja, ko, pt, es, tr.
* **Trend Observation:** This benchmark shows the lowest overall scores and the highest volatility. No model reaches the 0.9 outer ring.
* **Model Rankings:**
* **GPT-5.2:** Remains the leader, but scores drop to the 0.6 - 0.8 range.
* **Qwen3-VL:** Shows extreme volatility; performs relatively well in 'en' and 'ar' but crashes toward 0.3 in 'ja' and 'ko'.
* **Grok 4.1 Fast:** Generally follows the 0.4 - 0.5 ring.
* **Gemini 3 Pro:** Closely tracks Grok 4.1 Fast, often overlapping at the 0.4 - 0.5 level.
---
## 3. Language Code Reference
The following languages are represented by the labels on the charts:
| Code | Language | Code | Language |
| :--- | :--- | :--- | :--- |
| **ar** | Arabic | **it** | Italian |
| **zh** | Chinese | **ja** | Japanese |
| **cs** | Czech | **ko** | Korean |
| **nl** | Dutch | **pl** | Polish |
| **en** | English | **pt** | Portuguese |
| **fr** | French | **ru** | Russian |
| **de** | German | **es** | Spanish |
| **hi** | Hindi | **sv** | Swedish |
| **th** | Thai | **tr** | Turkish |
---
## 4. Summary of Findings
1. **Benchmark Difficulty:** PGP-P and PGP-R represent "easier" or more consistent tasks where all models perform well. ML-Bench-P and ML-Bench-R are significantly more challenging, revealing wide gaps in model capabilities.
2. **Model Hierarchy:** **GPT-5.2** is the top-performing model across all benchmarks and all languages. **Gemini 3 Pro** generally holds the second position. **Qwen3-VL** and **Grok 4.1 Fast** struggle significantly on the ML-Bench series, particularly in non-Western languages like Japanese (ja) and Korean (ko).