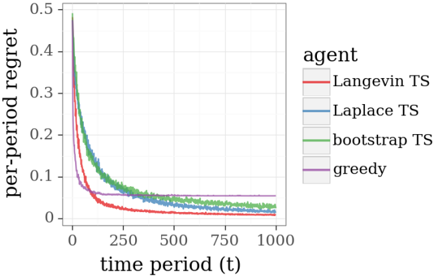
## Line Graph: Per-Period Regret Over Time
### Overview
The image is a line graph depicting the per-period regret of four different agents (Langevin TS, Laplace TS, bootstrap TS, and greedy) across 1,000 time periods. The y-axis represents "per-period regret" (0 to 0.5), and the x-axis represents "time period (t)" (0 to 1,000). The graph shows distinct trends for each agent, with regret decreasing over time for most agents.
---
### Components/Axes
- **Y-Axis**: "per-period regret" (0 to 0.5, increments of 0.1).
- **X-Axis**: "time period (t)" (0 to 1,000, increments of 250).
- **Legend**: Located on the right side of the graph, with four entries:
- **Red**: Langevin TS
- **Blue**: Laplace TS
- **Green**: bootstrap TS
- **Purple**: greedy
---
### Detailed Analysis
1. **Langevin TS (Red)**:
- Starts at ~0.5 regret at t=0.
- Drops sharply to ~0.05 by t=250.
- Remains near 0.05 for t > 250.
2. **Laplace TS (Blue)**:
- Starts at ~0.45 regret at t=0.
- Declines steeply to ~0.05 by t=250.
- Stabilizes near 0.05 for t > 250.
3. **bootstrap TS (Green)**:
- Starts at ~0.4 regret at t=0.
- Declines gradually to ~0.05 by t=500.
- Remains near 0.05 for t > 500.
4. **greedy (Purple)**:
- Starts at ~0.1 regret at t=0.
- Remains flat at ~0.1 for all t.
---
### Key Observations
- **Rapid Decline**: Langevin TS and Laplace TS exhibit the steepest initial declines in regret, converging to similar values by t=250.
- **Slower Adaptation**: bootstrap TS shows a slower decline, reaching near-zero regret only by t=500.
- **Static Performance**: The greedy agent maintains the lowest initial regret but shows no improvement over time.
- **Convergence**: All agents except greedy stabilize near 0.05 regret by t=1,000, suggesting diminishing returns for adaptive methods.
---
### Interpretation
The data demonstrates that **Langevin TS and Laplace TS** are highly effective at rapidly reducing regret, outperforming bootstrap TS and greedy in the early stages. The greedy agent’s static performance highlights its inability to adapt, despite starting with lower regret. The convergence of adaptive methods (Langevin, Laplace, bootstrap) toward similar regret values by t=1,000 suggests that their long-term performance plateaus, though their initial efficiency varies. This implies that while adaptive strategies are superior to greedy approaches, their benefits may diminish over extended periods. The graph underscores the importance of balancing exploration (via adaptive methods) and exploitation (via static strategies) in dynamic environments.