## Bar Chart: Indexical 'tomorrow'
### Overview
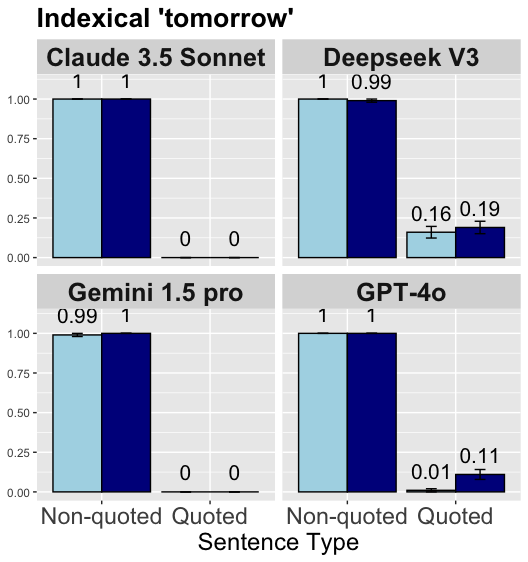
The image is a set of four bar charts comparing the performance of four different language models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, and GPT-4o) on a task involving the indexical term "tomorrow". The charts show the model's performance on two types of sentences: "Non-quoted" and "Quoted". The y-axis represents a score, presumably a probability or accuracy, ranging from 0.00 to 1.00. The bars are colored light blue and dark blue, representing different aspects of the model's performance. Error bars are present on some of the bars.
### Components/Axes
* **Title:** Indexical 'tomorrow'
* **X-axis:** Sentence Type, with categories "Non-quoted" and "Quoted"
* **Y-axis:** Scale from 0.00 to 1.00, incrementing by 0.25.
* **Chart Titles (Panels):**
* Claude 3.5 Sonnet (top-left)
* Deepseek V3 (top-right)
* Gemini 1.5 pro (bottom-left)
* GPT-4o (bottom-right)
* **Bar Colors:**
* Light Blue: Represents the first data series.
* Dark Blue: Represents the second data series.
### Detailed Analysis
**Claude 3.5 Sonnet (top-left)**
* Non-quoted: Light Blue bar at 1.00, Dark Blue bar at 1.00.
* Quoted: Light Blue bar at 0.00, Dark Blue bar at 0.00.
**Deepseek V3 (top-right)**
* Non-quoted: Light Blue bar at 1.00, Dark Blue bar at 0.99.
* Quoted: Light Blue bar at 0.16 (with error bars), Dark Blue bar at 0.19 (with error bars).
**Gemini 1.5 pro (bottom-left)**
* Non-quoted: Light Blue bar at 0.99, Dark Blue bar at 1.00.
* Quoted: Light Blue bar at 0.00, Dark Blue bar at 0.00.
**GPT-4o (bottom-right)**
* Non-quoted: Light Blue bar at 1.00, Dark Blue bar at 1.00.
* Quoted: Light Blue bar at 0.01 (with error bars), Dark Blue bar at 0.11 (with error bars).
### Key Observations
* Claude 3.5 Sonnet and Gemini 1.5 pro show similar performance, with perfect scores for non-quoted sentences and zero scores for quoted sentences.
* Deepseek V3 and GPT-4o perform well on non-quoted sentences but struggle with quoted sentences, with scores significantly above zero but still low.
* Error bars are present only for the "Quoted" sentence type in Deepseek V3 and GPT-4o, suggesting variability in their performance on this category.
* All models perform well on non-quoted sentences.
### Interpretation
The data suggests that all four language models are proficient at understanding the indexical term "tomorrow" in simple, non-quoted sentences. However, when the term is used within quotes, the models' performance varies significantly. Claude 3.5 Sonnet and Gemini 1.5 pro fail to understand the term in quoted sentences, while Deepseek V3 and GPT-4o show some understanding, albeit at a much lower level of accuracy. The presence of error bars for the "Quoted" sentence type in Deepseek V3 and GPT-4o indicates that their performance on this category is less consistent. This could be due to the models' difficulty in distinguishing between literal and figurative uses of the term "tomorrow" or their inability to handle the complexities of quoted speech. The difference in performance between the models highlights the challenges of natural language understanding, particularly in handling context and nuance.