\n
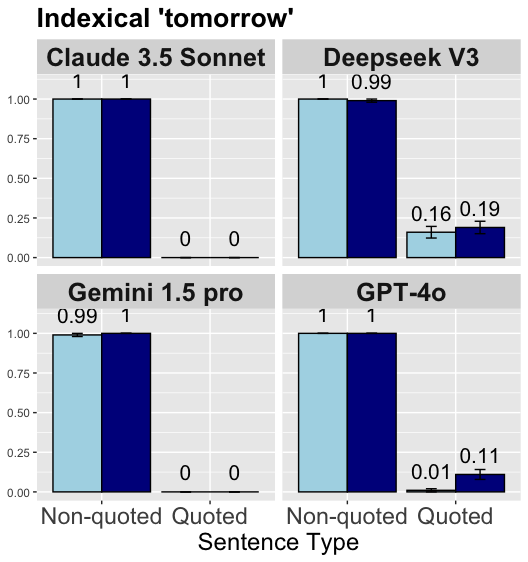
## Bar Chart: Indexical 'tomorrow' Performance
### Overview
The image presents a bar chart comparing the performance of four Large Language Models (LLMs) – Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, and GPT-4o – on understanding the indexical term "tomorrow" in both non-quoted and quoted sentence types. The performance metric appears to be a probability or accuracy score, ranging from 0 to 1. Error bars are present for Deepseek V3 and GPT-4o, indicating variance in their performance.
### Components/Axes
* **Title:** "Indexical 'tomorrow'" (top-center)
* **X-axis:** "Sentence Type" with two categories: "Non-quoted" and "Quoted".
* **Y-axis:** Scale ranging from 0.00 to 1.00, representing the performance score.
* **LLM Labels:** Each row represents a different LLM: "Claude 3.5 Sonnet", "Deepseek V3", "Gemini 1.5 pro", and "GPT-4o".
* **Bar Colors:** Light blue for "Non-quoted" sentences, dark blue for "Quoted" sentences.
* **Error Bars:** Present only for Deepseek V3 and GPT-4o, indicating standard error or confidence intervals.
### Detailed Analysis
The chart is divided into four sub-charts, one for each LLM. Each sub-chart contains two bars representing performance on "Non-quoted" and "Quoted" sentences.
**Claude 3.5 Sonnet:**
* Non-quoted: Score of 1.00.
* Quoted: Score of 1.00.
**Deepseek V3:**
* Non-quoted: Score of 1.00.
* Quoted: Score of approximately 0.18, with an error bar ranging from approximately 0.16 to 0.19.
**Gemini 1.5 pro:**
* Non-quoted: Score of 0.99.
* Quoted: Score of 0.00.
**GPT-4o:**
* Non-quoted: Score of 1.00.
* Quoted: Score of approximately 0.11, with an error bar ranging from approximately 0.01 to 0.11.
### Key Observations
* Claude 3.5 Sonnet and GPT-4o achieve perfect scores (1.00) on both non-quoted and quoted sentences.
* Deepseek V3 performs well on non-quoted sentences (1.00) but shows significantly lower performance on quoted sentences (approximately 0.18). The error bar indicates some variability in this performance.
* Gemini 1.5 pro performs well on non-quoted sentences (0.99) but fails to correctly interpret quoted sentences (0.00).
* There is a clear performance difference between non-quoted and quoted sentences for Deepseek V3 and Gemini 1.5 pro.
### Interpretation
The data suggests that the ability to correctly interpret the indexical term "tomorrow" is significantly affected by whether it is presented within a quoted sentence for Deepseek V3 and Gemini 1.5 pro. Quoting appears to introduce ambiguity or a change in context that these models struggle with. Claude 3.5 Sonnet and GPT-4o demonstrate a robust understanding of "tomorrow" regardless of sentence structure.
The error bars on Deepseek V3 and GPT-4o suggest that their performance on quoted sentences is less consistent than their performance on non-quoted sentences. This could be due to variations in the training data or the model's internal representation of context.
The zero score for Gemini 1.5 pro on quoted sentences is a notable outlier, indicating a complete failure to understand the meaning of "tomorrow" in that context. This could be a specific weakness of the model or a limitation of the evaluation methodology.
The chart highlights the importance of considering context when evaluating the performance of LLMs on tasks involving indexical terms. The ability to handle quoted speech and understand the nuances of context is crucial for achieving human-level language understanding.