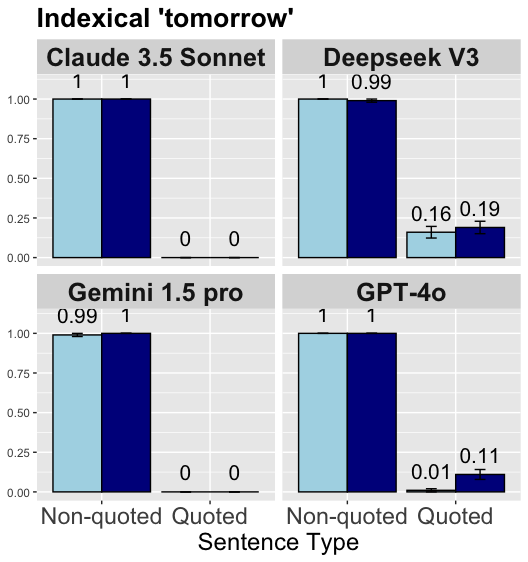
## [Bar Chart]: Indexical 'tomorrow' (AI Model Performance by Sentence Type)
### Overview
This is a grouped bar chart comparing the performance of four AI models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 pro, GPT-4o) on a task related to the indexical term "tomorrow," across two sentence types: *Non-quoted* (light blue bars) and *Quoted* (dark blue bars). The y-axis represents a numerical score (0.00–1.00, likely a probability or accuracy metric), and the x-axis labels the sentence type.
### Components/Axes
- **Title**: "Indexical 'tomorrow'" (top of the chart).
- **Y-axis**: Vertical scale with values `0.00`, `0.25`, `0.50`, `0.75`, `1.00` (left side, representing the performance score).
- **X-axis**: Horizontal axis labeled "Sentence Type" with two categories: *Non-quoted* and *Quoted* (bottom of the chart).
- **Legend**: Two colors:
- Light blue = *Non-quoted* sentence type.
- Dark blue = *Quoted* sentence type.
- **Models**: Four panels (2×2 grid) for each AI model:
- Top-left: Claude 3.5 Sonnet
- Top-right: Deepseek V3
- Bottom-left: Gemini 1.5 pro
- Bottom-right: GPT-4o
### Detailed Analysis (Per Model)
We analyze each model’s performance for *Non-quoted* (light blue) and *Quoted* (dark blue) sentence types, plus any additional bars (with error bars) in some panels:
1. **Claude 3.5 Sonnet (Top-Left Panel)**
- *Non-quoted* (light blue): Bar height = `1.00` (perfect score).
- *Quoted* (dark blue): Bar height = `1.00` (perfect score).
- No additional bars.
2. **Deepseek V3 (Top-Right Panel)**
- *Non-quoted* (light blue): Bar height = `1.00` (perfect score).
- *Quoted* (dark blue): Bar height = `0.99` (near-perfect score).
- Additional bars (with error bars):
- Light blue (likely a secondary metric): `0.16`
- Dark blue (likely a secondary metric): `0.19`
3. **Gemini 1.5 pro (Bottom-Left Panel)**
- *Non-quoted* (light blue): Bar height = `0.99` (near-perfect score).
- *Quoted* (dark blue): Bar height = `1.00` (perfect score).
- No additional bars.
4. **GPT-4o (Bottom-Right Panel)**
- *Non-quoted* (light blue): Bar height = `1.00` (perfect score).
- *Quoted* (dark blue): Bar height = `1.00` (perfect score).
- Additional bars (with error bars):
- Light blue (likely a secondary metric): `0.01`
- Dark blue (likely a secondary metric): `0.11`
### Key Observations
- **Primary Task (Non-quoted vs. Quoted)**: Most models achieve near-perfect or perfect scores (≥0.99) for both sentence types, indicating strong performance in handling the indexical "tomorrow" in non-quoted and quoted contexts.
- **Variations**:
- Deepseek V3 has a minor drop in *Quoted* (0.99) vs. *Non-quoted* (1.00).
- Gemini 1.5 pro has a minor drop in *Non-quoted* (0.99) vs. *Quoted* (1.00).
- **Secondary Metrics (Additional Bars)**: Deepseek V3 and GPT-4o have lower scores (0.16–0.19, 0.01–0.11) for a secondary metric (unlabeled, but visible as smaller bars with error bars), suggesting weaker performance in a related sub-task.
### Interpretation
The chart demonstrates that all four AI models perform exceptionally well (≥0.99) on the primary task of handling the indexical "tomorrow" in both non-quoted and quoted sentences. This suggests robust semantic understanding of temporal indexicals across sentence contexts. The minor variations (e.g., Deepseek V3’s 0.99 in *Quoted*) and secondary metric scores (e.g., GPT-4o’s 0.01) highlight subtle differences in model capabilities, possibly related to nuanced contextual interpretation or sub-task performance. The high primary-task scores imply that these models are well-suited for tasks requiring accurate handling of temporal indexicals in quoted/non-quoted speech.
(Note: The secondary metric bars (0.16, 0.19, 0.01, 0.11) lack explicit labels, so their exact meaning is inferred from context. The primary comparison (Non-quoted vs. Quoted) is clear and well-supported by the bar heights.)