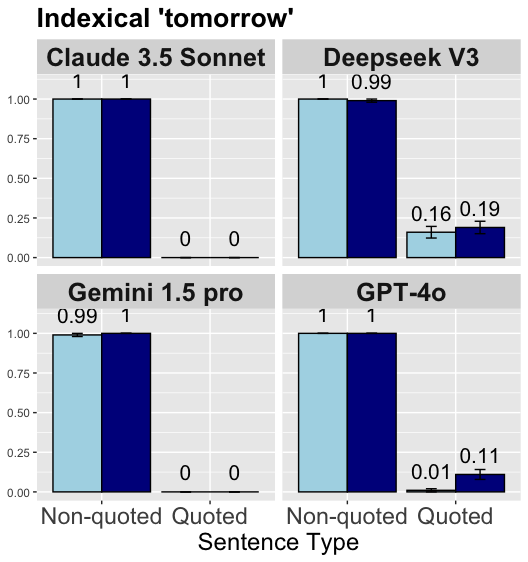
## Bar Chart: Indexical 'tomorrow' Performance Comparison
### Overview
The chart compares the performance of four AI models (Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 Pro, GPT-4o) across two sentence types: Non-quoted and Quoted. Values range from 0 to 1.0 on the y-axis, with error bars indicating uncertainty for some data points.
### Components/Axes
- **Title**: "Indexical 'tomorrow'"
- **X-axis**: "Sentence Type" (categories: Non-quoted, Quoted)
- **Y-axis**: Unlabeled, scaled 0–1.0
- **Legend**:
- Light blue = Non-quoted
- Dark blue = Quoted
- **Layout**: 2x2 grid of model-specific subplots (top-left to bottom-right: Claude 3.5 Sonnet, Deepseek V3, Gemini 1.5 Pro, GPT-4o)
### Detailed Analysis
1. **Claude 3.5 Sonnet**
- Non-quoted: 1.0 (no error bar)
- Quoted: 1.0 (no error bar)
2. **Deepseek V3**
- Non-quoted: 1.0 (no error bar)
- Quoted: 0.99 (±0.16 error bar)
3. **Gemini 1.5 Pro**
- Non-quoted: 0.99 (±0.01 error bar)
- Quoted: 1.0 (no error bar)
4. **GPT-4o**
- Non-quoted: 1.0 (no error bar)
- Quoted: 0.11 (±0.01 error bar)
### Key Observations
- **High Consistency**: All models achieve near-perfect scores (1.0 or 0.99) for Non-quoted sentences.
- **Quoted Sentence Variability**:
- Deepseek V3 and Gemini 1.5 Pro show minor drops (0.99 vs. 1.0) with moderate error margins.
- GPT-4o exhibits a drastic performance drop (0.11) for Quoted sentences, with a narrow error margin (±0.01).
- **Error Bar Patterns**: Only Deepseek V3 and GPT-4o include error bars, suggesting uncertainty in Quoted performance for these models.
### Interpretation
The data reveals a critical trend: **Quoted sentences significantly impact model performance**, particularly for GPT-4o, which shows a 90% drop (1.0 → 0.11) in quoted contexts. This suggests potential challenges in handling quoted content, possibly due to syntactic or semantic complexities. Deepseek V3’s larger error margin (±0.16) for Quoted sentences indicates higher variability in its performance compared to others. Claude 3.5 Sonnet and Gemini 1.5 Pro demonstrate robustness across both sentence types, though Gemini’s Non-quoted score (0.99) slightly lags behind Claude’s perfect 1.0. The absence of error bars for most models implies confidence in their Non-quoted performance, while the presence of error bars for Deepseek V3 and GPT-4o highlights uncertainty in quoted contexts. This disparity underscores the need for targeted improvements in models’ ability to process quoted text, which may involve refining syntactic parsing or contextual understanding mechanisms.