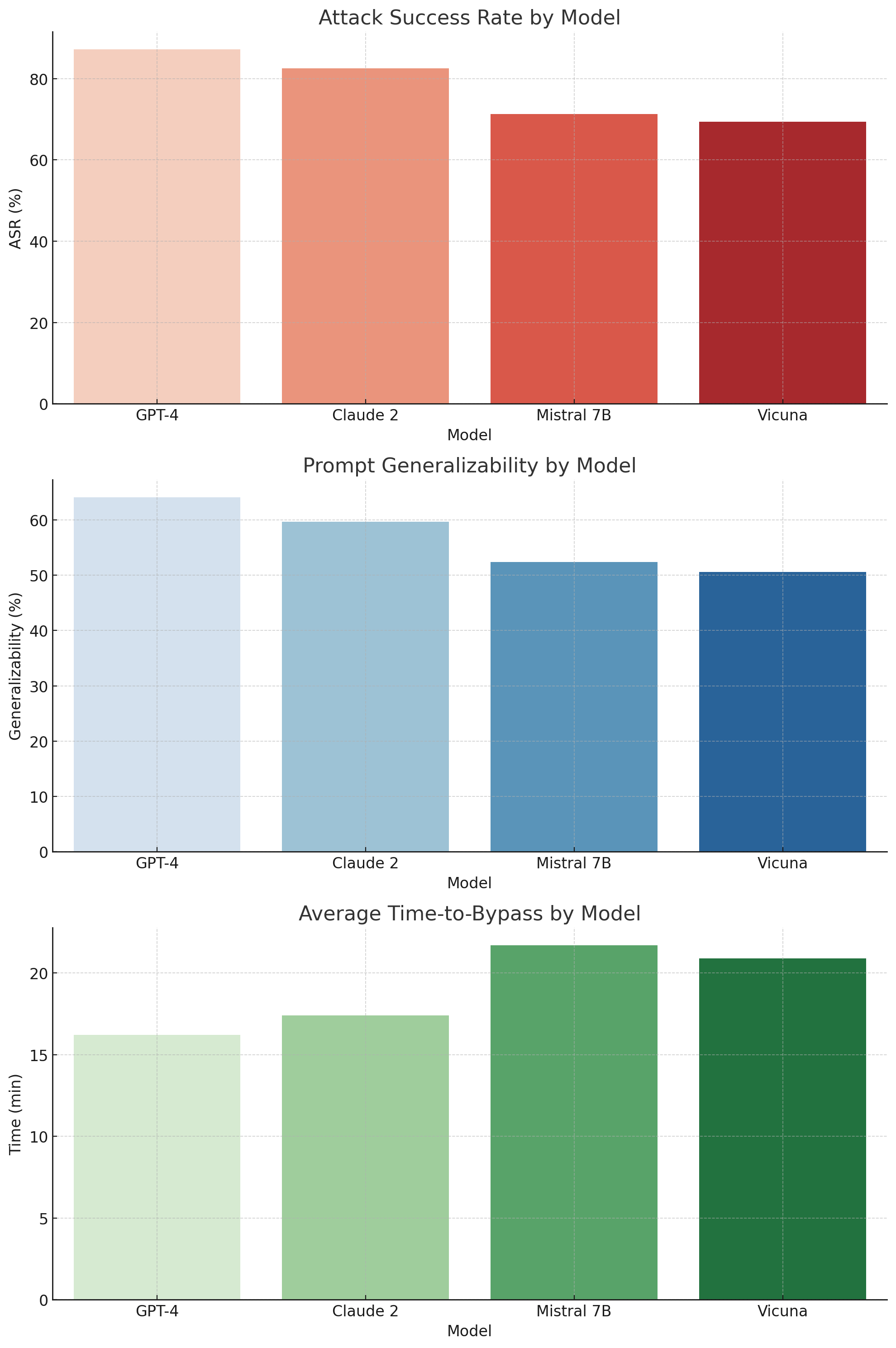
## Bar Charts: Model Performance Comparison
### Overview
The image presents three bar charts comparing the performance of four language models (GPT-4, Claude 2, Mistral 7B, and Vicuna) across three metrics: Attack Success Rate (ASR), Prompt Generalizability, and Average Time-to-Bypass. Each chart displays the metric value for each model using vertical bars of varying colors.
### Components/Axes
**Chart 1: Attack Success Rate by Model**
* **Title:** Attack Success Rate by Model
* **Y-axis:** ASR (%) with ticks at 0, 20, 40, 60, and 80.
* **X-axis:** Model, with labels GPT-4, Claude 2, Mistral 7B, and Vicuna.
* **Bar Colors:** The bars are shaded in a gradient of red, from light red (GPT-4) to dark red (Vicuna).
**Chart 2: Prompt Generalizability by Model**
* **Title:** Prompt Generalizability by Model
* **Y-axis:** Generalizability (%) with ticks at 0, 10, 20, 30, 40, 50, and 60.
* **X-axis:** Model, with labels GPT-4, Claude 2, Mistral 7B, and Vicuna.
* **Bar Colors:** The bars are shaded in a gradient of blue, from light blue (GPT-4) to dark blue (Vicuna).
**Chart 3: Average Time-to-Bypass by Model**
* **Title:** Average Time-to-Bypass by Model
* **Y-axis:** Time (min) with ticks at 0, 5, 10, 15, and 20.
* **X-axis:** Model, with labels GPT-4, Claude 2, Mistral 7B, and Vicuna.
* **Bar Colors:** The bars are shaded in a gradient of green, from light green (GPT-4) to dark green (Vicuna).
### Detailed Analysis
**Chart 1: Attack Success Rate by Model**
* **GPT-4:** ASR is approximately 87%.
* **Claude 2:** ASR is approximately 83%.
* **Mistral 7B:** ASR is approximately 72%.
* **Vicuna:** ASR is approximately 69%.
Trend: The attack success rate decreases from GPT-4 to Vicuna.
**Chart 2: Prompt Generalizability by Model**
* **GPT-4:** Generalizability is approximately 63%.
* **Claude 2:** Generalizability is approximately 60%.
* **Mistral 7B:** Generalizability is approximately 52%.
* **Vicuna:** Generalizability is approximately 50%.
Trend: The prompt generalizability decreases from GPT-4 to Vicuna.
**Chart 3: Average Time-to-Bypass by Model**
* **GPT-4:** Time-to-Bypass is approximately 16 minutes.
* **Claude 2:** Time-to-Bypass is approximately 17 minutes.
* **Mistral 7B:** Time-to-Bypass is approximately 20 minutes.
* **Vicuna:** Time-to-Bypass is approximately 21 minutes.
Trend: The average time-to-bypass increases from GPT-4 to Vicuna.
### Key Observations
* GPT-4 has the highest attack success rate and prompt generalizability, but the lowest average time-to-bypass.
* Vicuna has the lowest attack success rate and prompt generalizability, but the highest average time-to-bypass.
* Claude 2 performs similarly to GPT-4 in terms of attack success rate and prompt generalizability, but has a slightly higher average time-to-bypass.
* Mistral 7B performs worse than GPT-4 and Claude 2 in terms of attack success rate and prompt generalizability, but has a higher average time-to-bypass.
### Interpretation
The data suggests that GPT-4 is the most vulnerable model in terms of attack success rate and prompt generalizability, but it is also the easiest to bypass. Vicuna, on the other hand, is the least vulnerable model, but it is also the most difficult to bypass. Claude 2 and Mistral 7B fall somewhere in between.
These findings could be used to inform the development of more robust language models that are less vulnerable to attacks and more difficult to bypass. They also highlight the trade-off between security and usability, as the most secure model (Vicuna) is also the most difficult to use.