\n
## Bar Charts: Model Security Evaluation
### Overview
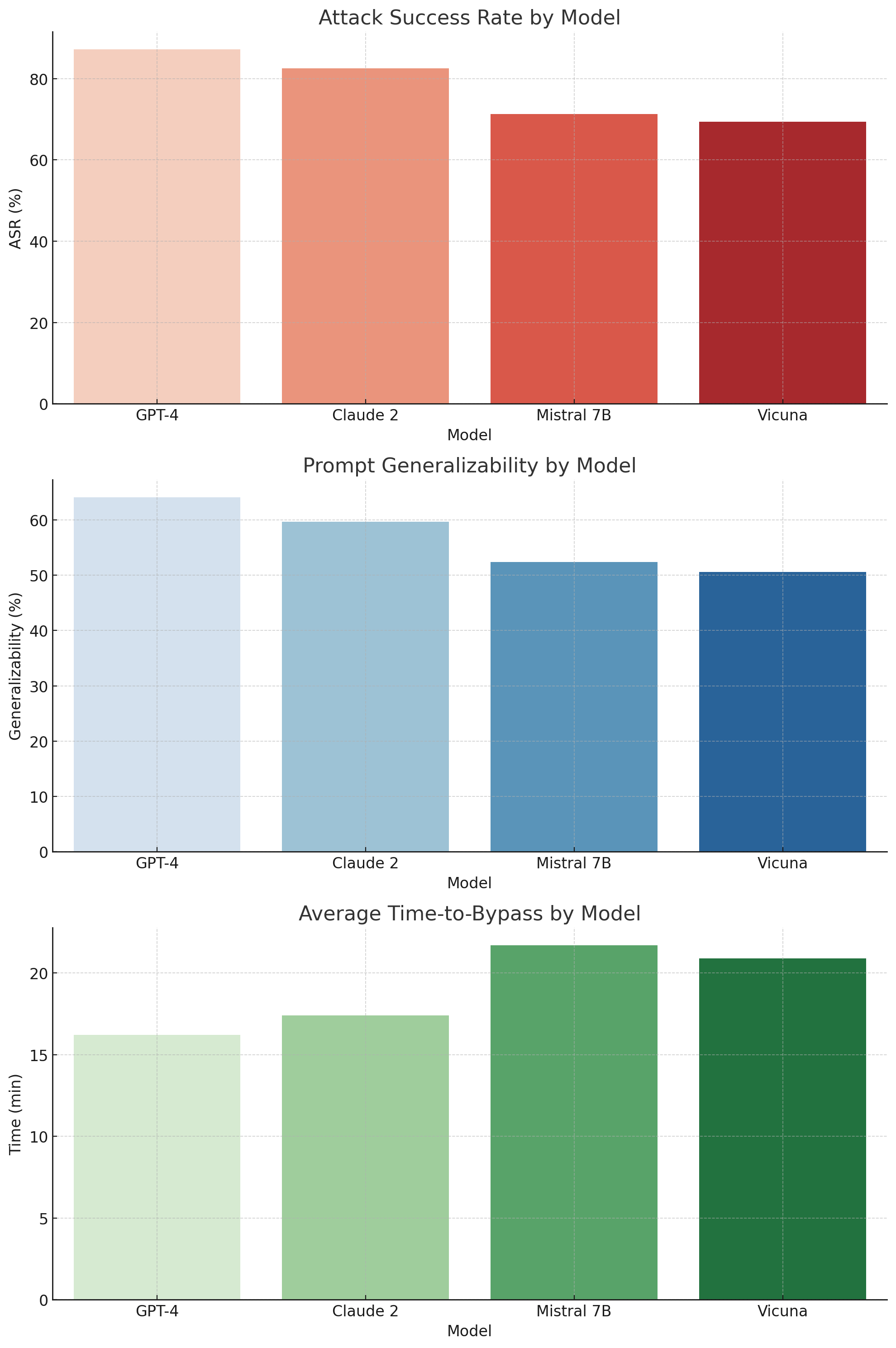
The image presents three stacked bar charts comparing the security performance of four Large Language Models (LLMs): GPT-4, Claude 2, Mistral 7B, and Vicuna. The charts evaluate the models across three metrics: Attack Success Rate (ASR), Prompt Generalizability, and Average Time-to-Bypass. Each chart uses the same x-axis representing the models.
### Components/Axes
* **X-axis (all charts):** "Model" with categories: GPT-4, Claude 2, Mistral 7B, Vicuna.
* **Chart 1: Attack Success Rate by Model**
* **Y-axis:** "ASR (%)" ranging from 0 to 80.
* **Bars:** Red bars representing the Attack Success Rate for each model.
* **Chart 2: Prompt Generalizability by Model**
* **Y-axis:** "Generalizability (%)" ranging from 0 to 60.
* **Bars:** Light blue bars representing the Prompt Generalizability for each model.
* **Chart 3: Average Time-to-Bypass by Model**
* **Y-axis:** "Time (min)" ranging from 0 to 20.
* **Bars:** Green bars representing the Average Time-to-Bypass for each model.
### Detailed Analysis or Content Details
**Chart 1: Attack Success Rate by Model**
* GPT-4: Approximately 75% ASR.
* Claude 2: Approximately 65% ASR.
* Mistral 7B: Approximately 70% ASR.
* Vicuna: Approximately 60% ASR.
The bars show that GPT-4 has the highest ASR, followed by Mistral 7B, Claude 2, and then Vicuna.
**Chart 2: Prompt Generalizability by Model**
* GPT-4: Approximately 50% Generalizability.
* Claude 2: Approximately 30% Generalizability.
* Mistral 7B: Approximately 55% Generalizability.
* Vicuna: Approximately 50% Generalizability.
Mistral 7B exhibits the highest prompt generalizability, followed by GPT-4 and Vicuna, with Claude 2 showing the lowest.
**Chart 3: Average Time-to-Bypass by Model**
* GPT-4: Approximately 13 minutes.
* Claude 2: Approximately 8 minutes.
* Mistral 7B: Approximately 16 minutes.
* Vicuna: Approximately 18 minutes.
Vicuna has the longest average time-to-bypass, followed by Mistral 7B, GPT-4, and then Claude 2.
### Key Observations
* GPT-4 is most vulnerable to attacks (highest ASR) but has relatively good prompt generalizability and a moderate time-to-bypass.
* Claude 2 is the most resistant to attacks (lowest ASR) but has the lowest prompt generalizability and a short time-to-bypass.
* Mistral 7B has high ASR and prompt generalizability, but a long time-to-bypass.
* Vicuna has moderate ASR and prompt generalizability, with the longest time-to-bypass.
### Interpretation
The data suggests a trade-off between security and usability/generalizability in these LLMs. Models that are more resistant to attacks (like Claude 2) may be less flexible and adaptable to different prompts. Conversely, models that are more generalizable (like Mistral 7B) may be more susceptible to attacks. GPT-4 and Vicuna represent intermediate positions on this spectrum.
The Attack Success Rate (ASR) indicates how easily an attacker can successfully prompt the model to generate undesirable outputs. Prompt Generalizability measures the model's ability to handle a variety of prompts without significant performance degradation. Time-to-Bypass represents the effort required for an attacker to circumvent the model's security measures.
The differences in Time-to-Bypass could be due to varying levels of security mechanisms implemented in each model. The higher ASR of GPT-4 and Mistral 7B could be attributed to their more open and flexible architectures, which may inadvertently create vulnerabilities. Claude 2's lower ASR might be a result of more restrictive safety filters, but at the cost of generalizability. Vicuna's long time-to-bypass suggests robust security measures, but its moderate ASR indicates that these measures are not foolproof.