## Bar Charts: Attack Success Rate, Prompt Generalizability, and Time-to-Bypass by Model
### Overview
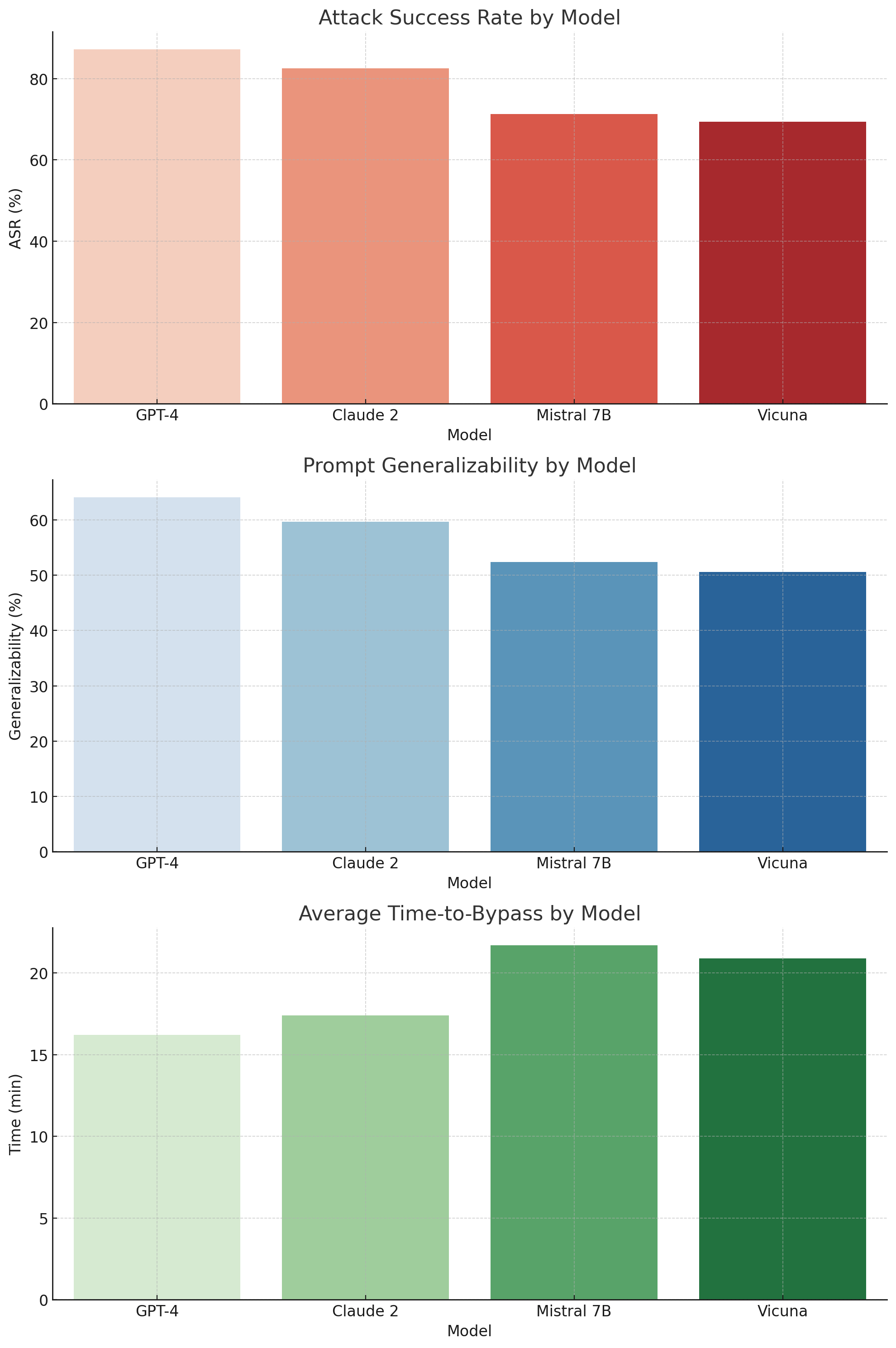
The image contains three vertically stacked bar charts comparing four large language models (LLMs) across three security-related metrics: Attack Success Rate (ASR), Prompt Generalizability, and Average Time-to-Bypass. The models evaluated are GPT-4, Claude 2, Mistral 7B, and Vicuna. Each chart uses a distinct color gradient (red, blue, green) to represent the data series.
### Components/Axes
**Common Elements:**
* **X-axis (all charts):** Labeled "Model". Categories from left to right: GPT-4, Claude 2, Mistral 7B, Vicuna.
* **Chart Titles (top to bottom):**
1. "Attack Success Rate by Model"
2. "Prompt Generalizability by Model"
3. "Average Time-to-Bypass by Model"
* **Grid:** Light gray, dashed horizontal grid lines are present in all charts.
**Chart 1: Attack Success Rate by Model**
* **Y-axis:** Labeled "ASR (%)". Scale from 0 to 80, with major ticks at 0, 20, 40, 60, 80.
* **Data Series Color:** A red gradient, from lightest (GPT-4) to darkest (Vicuna).
**Chart 2: Prompt Generalizability by Model**
* **Y-axis:** Labeled "Generalizability (%)". Scale from 0 to 60, with major ticks at 0, 10, 20, 30, 40, 50, 60.
* **Data Series Color:** A blue gradient, from lightest (GPT-4) to darkest (Vicuna).
**Chart 3: Average Time-to-Bypass by Model**
* **Y-axis:** Labeled "Time (min)". Scale from 0 to 20, with major ticks at 0, 5, 10, 15, 20.
* **Data Series Color:** A green gradient, from lightest (GPT-4) to darkest (Vicuna).
### Detailed Analysis
**Chart 1: Attack Success Rate (ASR)**
* **Trend:** The ASR shows a clear downward trend from left to right. GPT-4 has the highest success rate, and Vicuna has the lowest among the four.
* **Data Points (Approximate):**
* GPT-4: ~87% (Bar extends above the 80% line)
* Claude 2: ~82% (Bar is slightly above the 80% line)
* Mistral 7B: ~71% (Bar is midway between 60% and 80%)
* Vicuna: ~69% (Bar is slightly lower than Mistral 7B)
**Chart 2: Prompt Generalizability**
* **Trend:** Generalizability also shows a consistent downward trend from left to right. GPT-4 generalizes best, while Vicuna generalizes the least.
* **Data Points (Approximate):**
* GPT-4: ~64% (Bar extends above the 60% line)
* Claude 2: ~60% (Bar aligns with the 60% line)
* Mistral 7B: ~52% (Bar is slightly above the 50% line)
* Vicuna: ~50% (Bar aligns with the 50% line)
**Chart 3: Average Time-to-Bypass**
* **Trend:** The time required to bypass the model's safety measures shows an upward trend from left to right. GPT-4 is bypassed the fastest, while Mistral 7B and Vicuna require the most time.
* **Data Points (Approximate):**
* GPT-4: ~16 minutes (Bar is slightly above the 15-minute line)
* Claude 2: ~17.5 minutes (Bar is midway between 15 and 20)
* Mistral 7B: ~22 minutes (Bar extends above the 20-minute line)
* Vicuna: ~21 minutes (Bar is slightly lower than Mistral 7B)
### Key Observations
1. **Inverse Correlation:** There is a strong inverse relationship between Attack Success Rate/Generalizability and Time-to-Bypass. Models with higher ASR and generalizability (GPT-4, Claude 2) are bypassed more quickly. Models with lower ASR and generalizability (Mistral 7B, Vicuna) take longer to attack successfully.
2. **Model Grouping:** The models naturally form two groups: the higher-performing commercial models (GPT-4, Claude 2) and the open-source models (Mistral 7B, Vicuna). The commercial models are more susceptible to attacks but generalize better, while the open-source models are more resilient (take longer to break) but are less generalizable.
3. **Mistral 7B vs. Vicuna:** While their ASR and generalizability are similar, Mistral 7B has a slightly higher average bypass time than Vicuna, suggesting its defenses might be marginally more robust or consistent.
### Interpretation
The data suggests a fundamental trade-off in the current LLM landscape between capability (generalizability) and robustness (resistance to adversarial attacks). The more capable and general-purpose a model is (like GPT-4), the more "surface area" it presents for attacks, leading to higher success rates and faster bypass times. Conversely, models that are perhaps more constrained or less capable (Mistral 7B, Vicuna) exhibit greater resistance, requiring more effort and time from attackers to compromise.
This has significant implications for deployment. High-stakes applications requiring robust security might favor models with lower ASR and higher bypass times, even if it means sacrificing some generalizability. Applications prioritizing broad capability and flexibility might accept the higher attack risk associated with models like GPT-4. The charts do not show *why* these correlations exist, but they highlight a critical balancing act for developers and security teams when selecting and hardening LLMs.