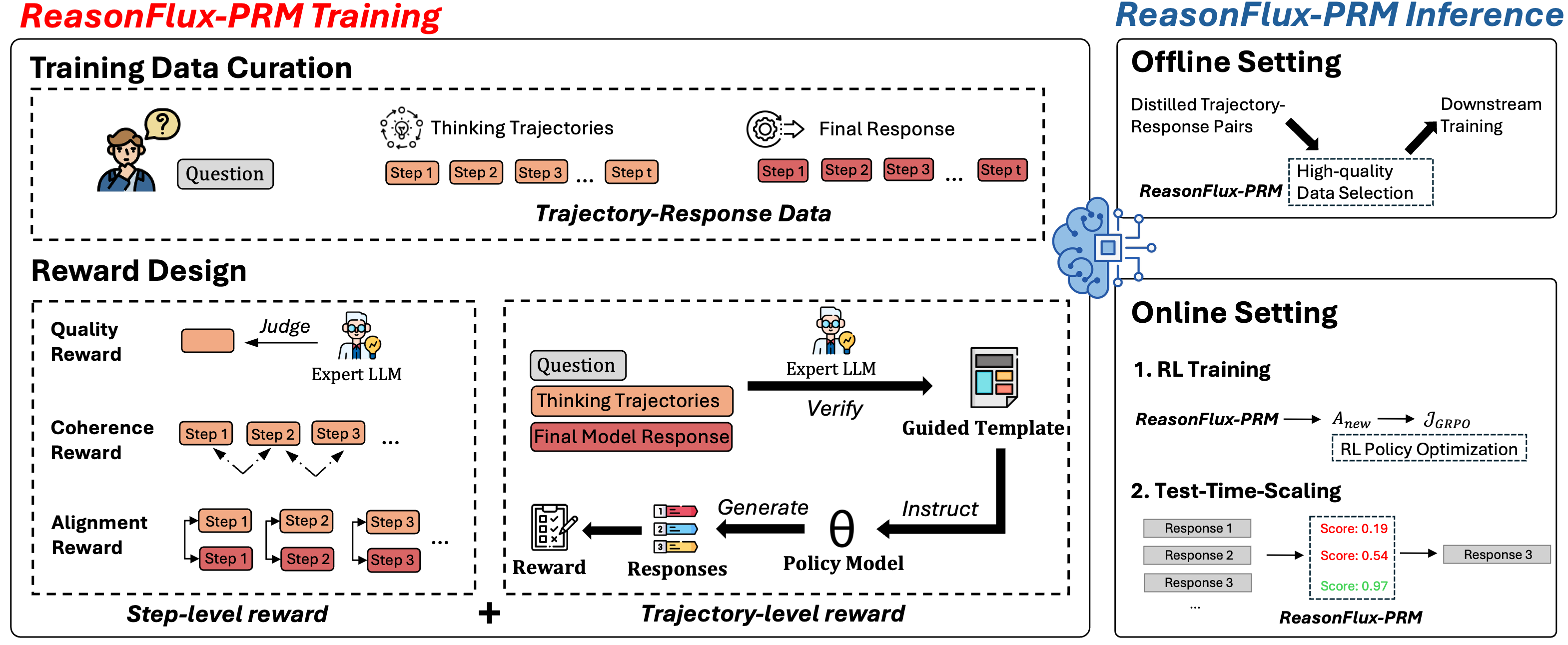
## Diagram: ReasonFlux-PRM Training and Inference
### Overview
The image presents a diagram illustrating the ReasonFlux-PRM framework, detailing both its training and inference processes. The diagram is divided into two main sections: "ReasonFlux-PRM Training" on the left and "ReasonFlux-PRM Inference" on the right. The training section covers data curation and reward design, while the inference section describes offline and online settings.
### Components/Axes
**ReasonFlux-PRM Training (Left Side):**
* **Header:** "ReasonFlux-PRM Training" in red text.
* **Training Data Curation:**
* A person icon with a question mark above their head, labeled "Question."
* "Thinking Trajectories" represented by a series of steps: "Step 1," "Step 2," "Step 3," ..., "Step t."
* "Final Response" also represented by a series of steps: "Step 1," "Step 2," "Step 3," ..., "Step t."
* The section is labeled "Trajectory-Response Data."
* **Reward Design:**
* "Quality Reward": An orange box labeled "Judge" pointing to an "Expert LLM" icon.
* "Coherence Reward": A series of steps "Step 1," "Step 2," "Step 3," with arrows indicating a flow or relationship between them.
* "Alignment Reward": Two parallel series of steps "Step 1," "Step 2," "Step 3," with arrows indicating a flow or relationship between them.
* "Step-level reward" is at the bottom of this section.
* A plus sign (+) connects "Step-level reward" to "Trajectory-level reward."
* "Trajectory-level reward" includes: "Question," "Thinking Trajectories," "Final Model Response."
* "Expert LLM" "Verify" "Guided Template"
* "Reward" "Responses" "Policy Model"
* "Generate" "Instruct" "θ"
**ReasonFlux-PRM Inference (Right Side):**
* **Header:** "ReasonFlux-PRM Inference" in blue text.
* **Offline Setting:**
* "Distilled Trajectory-Response Pairs" flowing into "High-quality Data Selection."
* "Downstream Training" also flowing from "High-quality Data Selection."
* "ReasonFlux-PRM" is associated with "High-quality Data Selection."
* **Online Setting:**
* "1. RL Training":
* "ReasonFlux-PRM" -> "Anew" -> "JGRPO"
* "RL Policy Optimization" is below the arrow.
* "2. Test-Time-Scaling":
* "Response 1" -> "Score: 0.19"
* "Response 2" -> "Score: 0.54"
* "Response 3" -> "Score: 0.97"
* "Response 3" is the final output.
* "ReasonFlux-PRM" is below the responses.
### Detailed Analysis or ### Content Details
* **Training Data Curation:** This section focuses on gathering data for training the ReasonFlux-PRM model. It starts with a question and generates thinking trajectories and final responses.
* **Reward Design:** This section describes how rewards are designed to guide the model's learning process. It includes quality, coherence, and alignment rewards at the step level, combined with trajectory-level rewards.
* **Offline Setting:** This setting involves using distilled trajectory-response pairs to select high-quality data for downstream training.
* **Online Setting:** This setting includes RL training, where ReasonFlux-PRM is used to optimize a policy. It also includes test-time scaling, where responses are scored and refined.
### Key Observations
* The diagram highlights the flow of data and processes in both training and inference stages.
* The training stage involves curating data and designing rewards to guide the model.
* The inference stage includes offline and online settings, each with its own processes.
* The online setting uses RL training and test-time scaling to refine the model's responses.
### Interpretation
The diagram illustrates the ReasonFlux-PRM framework as a comprehensive system for training and deploying language models. The training process emphasizes data quality and reward design, ensuring the model learns effectively. The inference process offers flexibility through offline and online settings, allowing the model to adapt to different scenarios. The use of RL training and test-time scaling in the online setting suggests a focus on continuous improvement and refinement of the model's responses. The diagram suggests a cyclical process of training, inference, and refinement, indicating a commitment to ongoing improvement of the ReasonFlux-PRM model.