\n
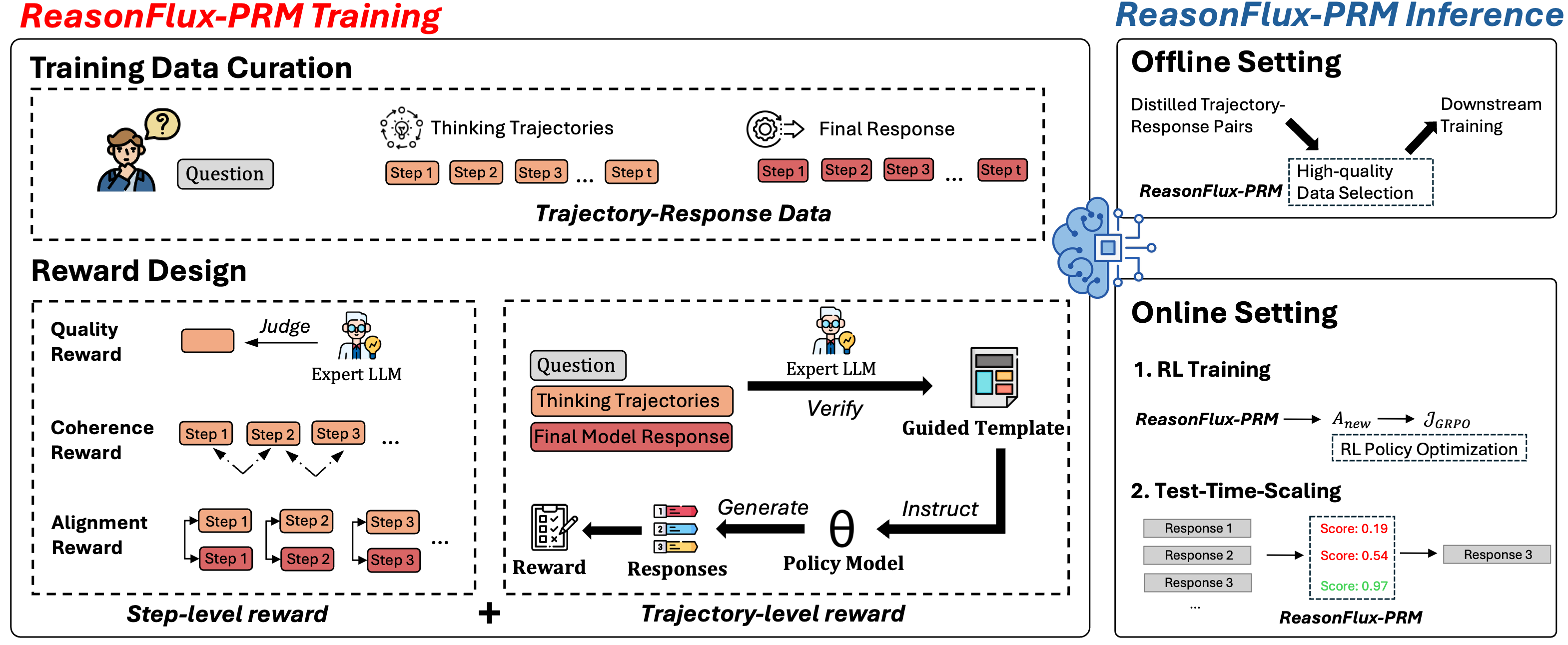
## Diagram: ReasonFlux-PRM Training and Inference
### Overview
This diagram illustrates the training and inference processes of the ReasonFlux-PRM system. The diagram is divided into two main sections: "ReasonFlux-PRM Training" on the left and "ReasonFlux-PRM Inference" on the right. The training section details data curation and reward design, while the inference section outlines offline and online settings. The diagram uses a flowchart style with icons representing different components and processes.
### Components/Axes
The diagram is structured around several key components:
* **Training Data Curation:** Includes "Question", "Thinking Trajectories" (Step 1 to Step t), and "Final Response".
* **Reward Design:** Includes "Quality Reward", "Coherence Reward", and "Alignment Reward", each with associated "Step-level reward" and "Trajectory-level reward".
* **ReasonFlux-PRM:** Represented by a stylized brain icon.
* **Expert LLM:** Represented by a head icon, used for judging and verifying.
* **Policy Model:** Represented by a box with "Generate" and "Instruct" labels.
* **Offline Setting:** Includes "Distilled Trajectory-Response Pairs", "High-quality Data Selection", and "Downstream Training".
* **Online Setting:** Divided into "1. RL Training" and "2. Test-Time-Scaling".
* **RL Training:** Shows a flow from "ReasonFlux-PRM" to "A<sub>new</sub>" to "J<sub>GRPO</sub>" with "RL Policy Optimization".
* **Test-Time-Scaling:** Displays "Response 1", "Response 2", and "Response 3" with associated scores.
### Detailed Analysis or Content Details
**Training Data Curation:**
* A "Question" initiates the process.
* The question leads to "Thinking Trajectories" consisting of multiple steps (Step 1 to Step t).
* These trajectories culminate in a "Final Response".
* The trajectory-response data is used for reward design.
**Reward Design:**
* **Quality Reward:** An "Expert LLM" judges the quality.
* **Coherence Reward:** Evaluates the coherence of "Thinking Trajectories" (Step 1 to Step 3, with ellipsis indicating more steps).
* **Alignment Reward:** Assesses the alignment of "Thinking Trajectories" (Step 1 to Step 3, with ellipsis indicating more steps).
* Rewards are provided at both "Step-level" and "Trajectory-level".
**ReasonFlux-PRM Inference - Offline Setting:**
* "Distilled Trajectory-Response Pairs" are used for "High-quality Data Selection".
* This selection feeds into "Downstream Training".
**ReasonFlux-PRM Inference - Online Setting:**
* **RL Training:** "ReasonFlux-PRM" is optimized via "RL Policy Optimization" based on "A<sub>new</sub>" and "J<sub>GRPO</sub>".
* **Test-Time-Scaling:**
* Response 1: Score = 0.19
* Response 2: Score = 0.54
* Response 3: Score = 0.97
**Policy Model:**
* The "Policy Model" receives input and generates responses.
* It is instructed by the "ReasonFlux-PRM" system.
### Key Observations
* The diagram emphasizes the iterative nature of the training process, with multiple steps in the thinking trajectories.
* The reward design incorporates multiple dimensions (quality, coherence, alignment) to guide the learning process.
* The inference process has both offline (data-driven) and online (RL-based) components.
* The test-time scaling shows a clear improvement in scores from Response 1 to Response 3, suggesting successful optimization.
* The use of an "Expert LLM" for judging and verifying highlights the importance of human-level evaluation.
### Interpretation
The diagram illustrates a sophisticated framework for training and deploying a reasoning model (ReasonFlux-PRM). The system leverages a combination of trajectory-response data, reward signals, and reinforcement learning to improve its performance. The separation of training and inference into distinct stages allows for both data-driven learning and real-time adaptation. The increasing scores in the test-time scaling section suggest that the RL training is effective in optimizing the policy model. The use of an Expert LLM indicates a focus on aligning the model's reasoning with human expectations. The diagram suggests a closed-loop system where the model learns from its interactions and continuously improves its reasoning capabilities. The diagram is a high-level overview and does not provide specific details about the algorithms or implementation details. However, it effectively conveys the key components and processes involved in the ReasonFlux-PRM system.