## [Diagram]: ReasonFlux-PRM Training and Inference Framework
### Overview
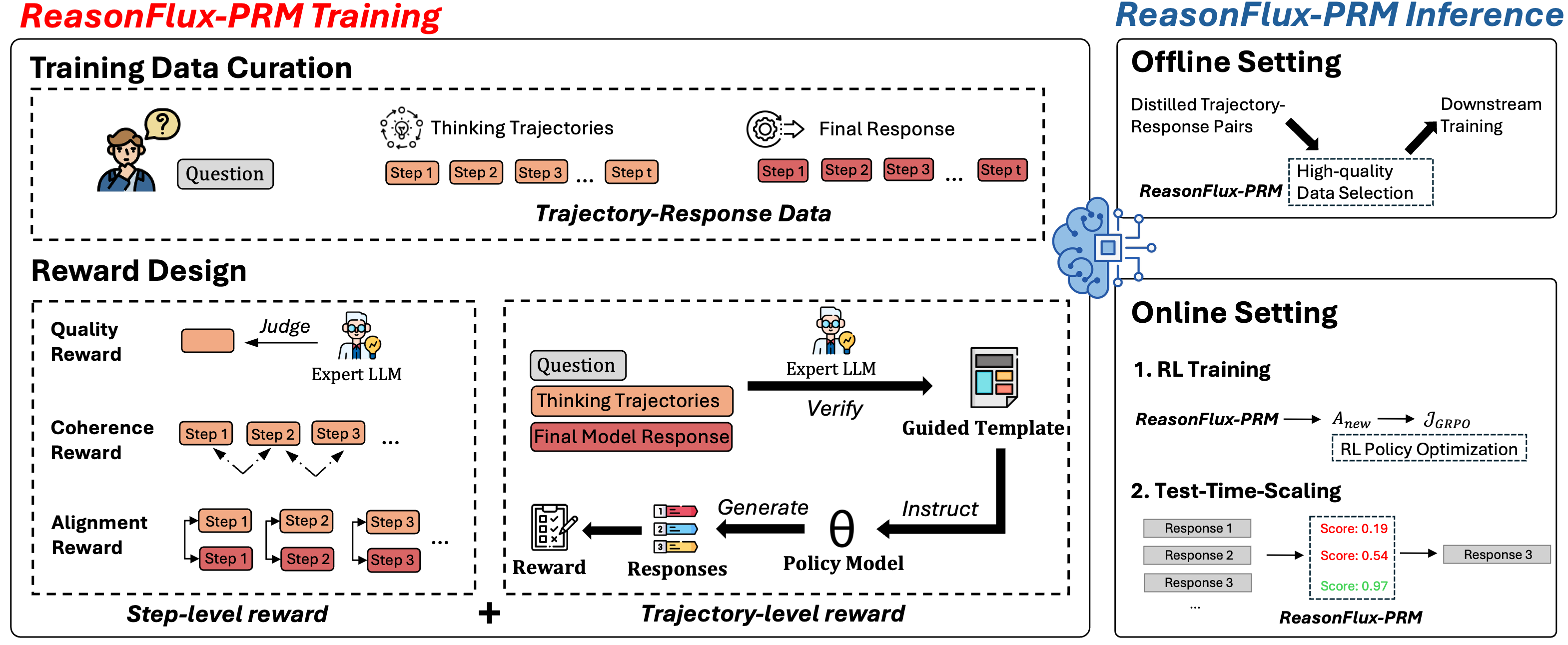
The image is a technical diagram illustrating the **ReasonFlux-PRM** framework, split into two primary sections: **ReasonFlux-PRM Training** (left) and **ReasonFlux-PRM Inference** (right). The Training section focuses on data curation and reward design, while Inference covers offline/online deployment.
### Components/Axes (Diagram Structure)
- **Top Headers**:
- Left: *"ReasonFlux-PRM Training"* (red text)
- Right: *"ReasonFlux-PRM Inference"* (blue text)
- **Training Section (Left)**:
- Subsections: *Training Data Curation* (dashed box) and *Reward Design* (dashed box).
- *Training Data Curation*:
- Elements: *"Question"* (icon: person with a question mark), *"Thinking Trajectories"* (icon: brain, steps: `Step 1`, `Step 2`, `Step 3`, ..., `Step t`), *"Final Response"* (icon: gear, steps: `Step 1`, `Step 2`, `Step 3`, ..., `Step t`), labeled *"Trajectory-Response Data"*.
- *Reward Design*:
- Split into *Step-level reward* (left) and *Trajectory-level reward* (right).
- *Step-level reward*:
- *"Quality Reward"* (orange box, arrow: *"Judge"* → *"Expert LLM"* icon).
- *"Coherence Reward"* (steps: `Step 1`, `Step 2`, `Step 3`, ... with arrows between them).
- *"Alignment Reward"* (steps: `Step 1`, `Step 2`, `Step 3`, ... with arrows between them).
- *Trajectory-level reward*:
- *"Question"* (box), *"Thinking Trajectories"* (orange box), *"Final Model Response"* (red box).
- *"Expert LLM"* icon with *"Verify"* arrow → *"Guided Template"* (document icon).
- *"Policy Model"* (θ symbol) with *"Instruct"* arrow from *"Guided Template"*.
- *"Generate"* arrow from *"Policy Model"* → *"Responses"* (list: `1`, `2`, `3`).
- *"Reward"* (clipboard icon) with arrow from *"Responses"*.
- **Inference Section (Right)**:
- Subsections: *Offline Setting* (dashed box) and *Online Setting* (dashed box).
- *Offline Setting*:
- *"Distilled Trajectory-Response Pairs"* (arrow → *"High-quality Data Selection"* box), *"ReasonFlux-PRM"* (label), *"Downstream Training"* (arrow from *"High-quality Data Selection"*).
- *Online Setting*:
- *"1. RL Training"*: *"ReasonFlux-PRM"* → *"A_new"* → *"J_GRPO"* (labeled *"RL Policy Optimization"*).
- *"2. Test-Time-Scaling"*: *"Response 1"* (Score: `0.19`), *"Response 2"* (Score: `0.54`), *"Response 3"* (Score: `0.97`) → *"Response 3"* (arrow), *"ReasonFlux-PRM"* (label).
### Detailed Analysis (Content Details)
- **Training Data Curation**:
- Input: *"Question"* (user query).
- Process: Generate *"Thinking Trajectories"* (step-by-step reasoning: `Step 1` to `Step t`) and *"Final Response"* (step-by-step output: `Step 1` to `Step t`).
- Output: *"Trajectory-Response Data"* (combines thinking steps and final response steps).
- **Reward Design**:
- *Step-level reward*:
- *"Quality Reward"*: Assessed by *"Expert LLM"* (judge icon).
- *"Coherence Reward"*: Evaluates logical flow between steps (arrows between `Step 1`, `Step 2`, `Step 3`, ...).
- *"Alignment Reward"*: Evaluates alignment between steps (arrows between `Step 1`, `Step 2`, `Step 3`, ...).
- *Trajectory-level reward*:
- *"Expert LLM"* verifies *"Question"*, *"Thinking Trajectories"*, and *"Final Model Response"* to create *"Guided Template"*.
- *"Policy Model"* (θ) is instructed by *"Guided Template"* to generate *"Responses"* (`1`, `2`, `3`).
- *"Reward"* is assigned to these responses.
- **Inference - Offline Setting**:
- *"Distilled Trajectory-Response Pairs"* are filtered via *"High-quality Data Selection"* (using ReasonFlux-PRM) for *"Downstream Training"*.
- **Inference - Online Setting**:
- *RL Training*: ReasonFlux-PRM optimizes policy (`A_new` → `J_GRPO`, *"RL Policy Optimization"*).
- *Test-Time-Scaling*: Responses (`1`, `2`, `3`) are scored (`0.19`, `0.54`, `0.97`) by ReasonFlux-PRM, with *"Response 3"* (highest score) selected.
### Key Observations
- **Color Coding**: Orange (thinking trajectories), red (final responses), blue (inference headers), red (training headers).
- **Icons**: Person (question), brain (thinking), gear (final response), expert LLM (judge/verifier), clipboard (reward), document (template).
- **Flow Arrows**: Indicate data curation → reward design → inference (offline/online).
- **Reward Hierarchy**: Step-level (quality/coherence/alignment) vs. Trajectory-level (verification/policy/reward).
### Interpretation
- **Training Phase**: Curates trajectory-response data (thinking + final steps) and designs rewards (step-level: quality/coherence/alignment; trajectory-level: verification/policy/reward) to train ReasonFlux-PRM.
- **Inference Phase**:
- *Offline*: Filters high-quality data for downstream training.
- *Online*: Uses RL to optimize policy and test-time scaling to select the best response (highest score).
- **Purpose**: The framework improves reasoning (via trajectory-based training) and inference (via RL/test-time scaling) by combining step-level and trajectory-level rewards, ensuring quality, coherence, and alignment in responses.
This diagram provides a comprehensive view of how ReasonFlux-PRM is trained (data curation + reward design) and deployed (offline/online inference) to enhance reasoning and response quality.