## Diagram: XAI Methods in LLMs
### Overview
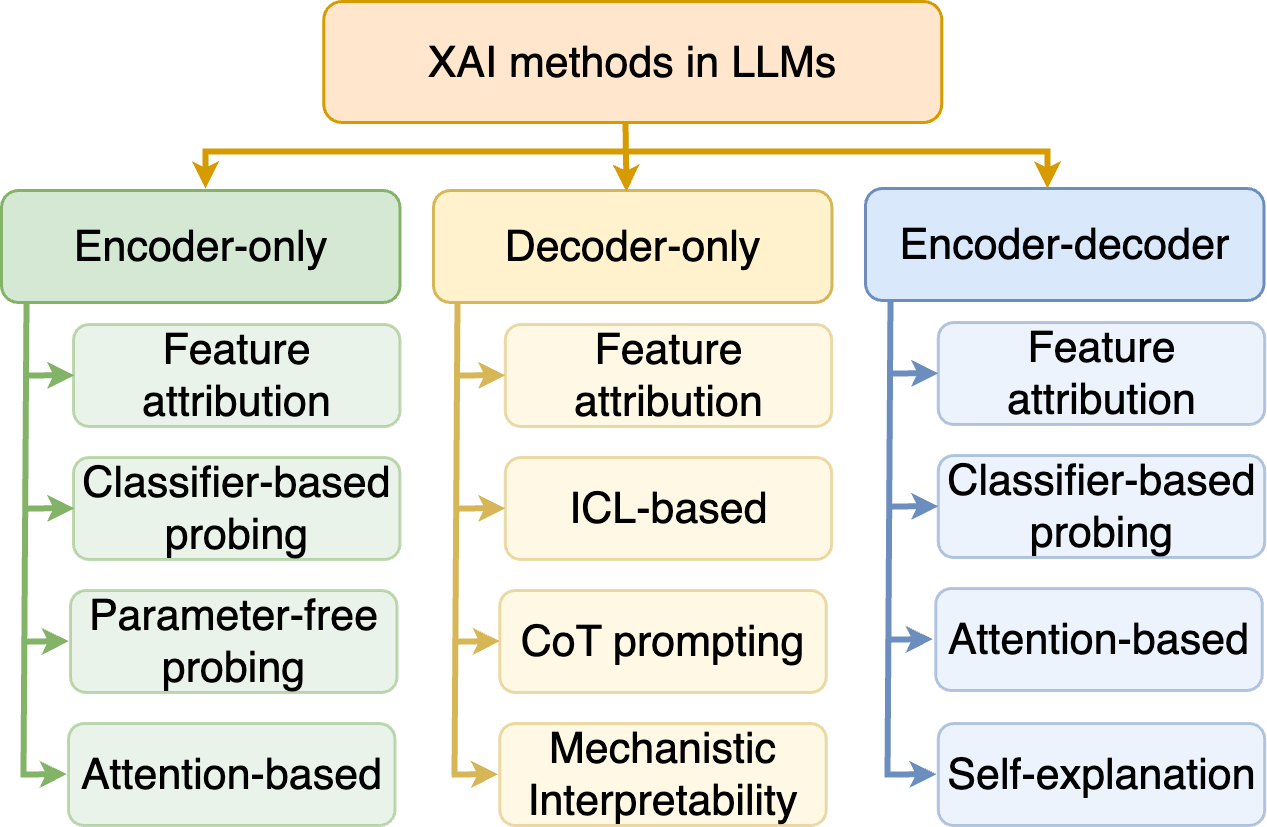
The image is a diagram illustrating different XAI (Explainable AI) methods used in Large Language Models (LLMs). It categorizes these methods based on the LLM architecture they are applied to: Encoder-only, Decoder-only, and Encoder-decoder. Each category lists specific XAI techniques.
### Components/Axes
* **Main Title:** XAI methods in LLMs (located at the top center)
* **Categories (Top Level):**
* Encoder-only (Green box, left side)
* Decoder-only (Yellow box, center)
* Encoder-decoder (Blue box, right side)
* **XAI Methods (Sub-categories):** Each category has a list of XAI methods associated with it. These are contained in rounded boxes.
### Detailed Analysis or ### Content Details
**1. Encoder-only (Green):**
* Feature attribution
* Classifier-based probing
* Parameter-free probing
* Attention-based
**2. Decoder-only (Yellow):**
* Feature attribution
* ICL-based
* CoT prompting
* Mechanistic Interpretability
**3. Encoder-decoder (Blue):**
* Feature attribution
* Classifier-based probing
* Attention-based
* Self-explanation
The arrows indicate the relationship between the LLM architecture type (Encoder-only, Decoder-only, Encoder-decoder) and the specific XAI methods applicable to each.
### Key Observations
* "Feature attribution" and "Classifier-based probing" are common XAI methods used across Encoder-only and Encoder-decoder architectures.
* "Feature attribution" is also used in Decoder-only architectures.
* Decoder-only architectures have unique methods like "ICL-based", "CoT prompting", and "Mechanistic Interpretability".
* Encoder-decoder architectures have a unique method called "Self-explanation".
* Encoder-only architectures have a unique method called "Parameter-free probing".
### Interpretation
The diagram provides a structured overview of XAI methods in the context of different LLM architectures. It highlights the diversity of techniques available for understanding and interpreting the behavior of these models. The categorization helps in selecting appropriate XAI methods based on the specific architecture being used. The presence of common methods across different architectures suggests fundamental interpretability approaches, while unique methods indicate architecture-specific considerations.